
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Langchain
- model context protocol
- rotary position embedding
- CoT
- flashattention
- gqa
- Positional Encoding
- Multi-Head Attention
- BLEU
- fréchet inception distance
- PEFT
- 토크나이저
- catastrophic forgetting
- attention
- MHA
- 트랜스포머
- context engineering
- SK AI SUMMIT 2025
- reinforcement learning from human feedback
- extended thinking
- RLHF
- langgraph
- self-attention
- chain-of-thought
- re-ranking
- Embedding
- MQA
- transformer
- test-time scaling
- Engineering at Anthropic
- Today
- Total
AI Engineer 공간 "사부작 사부작"
AI 모델 다이어트 비법, 양자화: LLM 경량화, 어디까지 왔나? 본문
AI 모델 다이어트 비법, 양자화: LLM 경량화, 어디까지 왔나?
ChoYongHo 2025. 5. 28. 21:37모델 경량화의 핵심, 양자화: PTQ, QAT 심층 분석과 GPTQ/AWQ 최신 동향
대규모 언어 모델(LLM)은 놀라운 가능성을 제시하지만, 그 거대한 크기와 막대한 연산량은 실제 서비스 환경에 부담을 줍니다. 마치 최첨단 기술이 집약된 거대한 엔진을 소형차에 탑재하려는 도전과 같습니다. 이 문제를 해결하는 핵심 기술 중 하나가 바로 양자화(Quantization)입니다. 양자화는 모델이 정보를 표현하고 계산하는 데 사용하는 숫자의 정밀도(비트 수)를 낮추는 기법입니다. 일반적으로 사용되는 32비트 부동소수점(FP32) 대신, 16비트 부동소수점(FP16, BF16)이나 8비트 정수(INT8) 등으로 변환하여 모델을 더 가볍고 빠르게 만듭니다. 고해상도 원본 이미지를 품질 손실은 최소화하면서 웹용으로 압축하는 과정에 비유할 수 있습니다. 본 글에서는 양자화의 주요 기법, 형식, 그리고 이들이 모델의 성능, 크기, 정확도에 미치는 영향을 전문가적 시각으로 상세히 살펴보겠습니다.
양자화, 왜 필수적인가? 모델 최적화의 열쇠
양자화는 모델 크기 감소를 넘어 다양한 이점을 제공합니다.
- 모델 크기 축소: 사용하는 비트 수를 줄여 모델 파일의 크기를 획기적으로 줄입니다. 이는 저장 공간이 제한된 엣지 디바이스 배포나 모델 로딩 시간 단축에 결정적입니다.
- 메모리 사용량 절감: 추론 시 필요한 메모리(RAM 또는 VRAM) 점유율을 낮춥니다. 특히 LLM의 KV 캐시처럼 메모리 집중적인 부분에서 효과가 두드러집니다.
- 추론 속도 향상: 메모리 대역폭 요구량이 감소하고, 일부 하드웨어(예: NVIDIA GPU의 텐서 코어)는 저정밀도 연산을 더 빠르게 처리하여 응답 속도를 개선합니다.
간단히 말해, 양자화는 복잡한 고정밀도 숫자를 더 단순한 저정밀도 숫자로 변환하되, 그 변환 기준을 기억하여 정보 손실을 최소화하는 과정입니다.
다양한 양자화 형식: 정밀도와 효율성의 균형
양자화에는 여러 수치 형식이 사용되며, 각 형식은 고유한 장단점을 지닙니다.
- FP32 (32비트 부동소수점): 양자화되지 않은 표준 고정밀도 형식입니다. 원본 설계도처럼 가장 많은 정보를 담고 있지만, 크고 무겁습니다.
- FP16 (16비트 부동소수점):
- 개념: FP32의 절반인 16비트로 숫자를 표현합니다.
- 장점: 속도와 정확도 간의 균형이 비교적 우수하며, 모델 크기를 절반으로 줄입니다.
- 단점: 표현 가능한 수의 범위가 좁아 오버플로우/언더플로우 문제가 발생할 수 있습니다.
- 비유: 정교한 제도용 연필로 그린 스케치와 같습니다. 대부분의 디테일을 잘 표현하지만, 극단적인 값 표현에는 한계가 있을 수 있습니다.
- BF16 (BFloat16):
- 개념: FP16과 동일한 16비트지만, 지수부(값의 범위 표현)는 FP32와 유사하게 넓고 가수부(값의 정밀도 표현)는 줄인 형태입니다.
- 장점: FP32와 유사한 넓은 표현 범위를 가져 수치적으로 안정적이며, 특히 모델 훈련에 유용합니다.
- 단점: 가수부 비트 수가 적어 FP16보다 정밀도 자체는 다소 낮을 수 있습니다.
- 비유: 광각 렌즈 카메라와 같습니다. 넓은 범위의 값을 안정적으로 포착하지만, 아주 미세한 질감 표현은 FP16보다 약간 덜 선명할 수 있습니다.
- INT8 (8비트 정수):
- 개념: 8비트 정수로 값을 표현하며, 부동소수점 값을 변환하기 위한 스케일링 계수 등이 필요합니다.
- 장점: 모델 크기를 가장 크게 줄이고, INT8 연산 지원 하드웨어에서 가장 큰 속도 향상을 기대할 수 있습니다.
- 단점: 정보 손실 가능성이 커, 정확도 하락을 최소화하기 위한 세심한 보정(calibration) 과정이 중요합니다.
- 비유: 세상의 모든 색을 256개의 크레용으로 표현하는 것과 같습니다. 원본의 색감을 최대한 살리려면 어떤 크레용을 선택할지 신중해야 합니다.
주요 양자화 기법: PTQ 대 QAT
양자화 적용 시점과 방식에 따라 크게 두 가지 기법으로 나뉩니다.
1. 훈련 후 양자화 (Post-Training Quantization, PTQ)
- 개념: 이미 훈련된 FP32 모델을 가져와 추가 훈련 없이 가중치나 활성화 값을 저정밀도로 변환하는 방식입니다. 종종 소량의 보정 데이터를 사용하여 최적의 변환 매개변수를 찾습니다.
- 비유: 완성된 유화 그림(FP32 모델)을 제한된 색상의 크레용 세트(저정밀도)로 최대한 비슷하게 복제하는 것과 같습니다. 원본을 다시 그리지 않고, 현재 그림의 색상을 분석해 가장 적합한 크레용으로 대체합니다. 그림의 일부 조각(보정 데이터)을 참고해 기준을 정합니다.
- 장점: 구현이 비교적 간단하고 빠르며, 추가 훈련 비용이 적습니다.
- 단점: 모델이 양자화로 인한 오차를 학습할 기회가 없어, 특히 매우 낮은 비트로 양자화 시 정확도 손실이 QAT보다 클 수 있습니다.
2. 양자화 인식 훈련 (Quantization-Aware Training, QAT)
- 개념: 모델 훈련 또는 미세 조정(fine-tuning) 과정 중에 양자화 연산을 시뮬레이션(가짜 양자화 연산 삽입)합니다. 모델이 양자화로 인한 오차를 미리 경험하고 이에 강건해지도록 학습합니다.
- 비유: 그림을 처음 배울 때부터 "이 작은 크레용 세트(저정밀도)만 사용해야 한다"는 지침을 받는 상황과 같습니다. 화가는 제한된 도구 안에서 최상의 표현을 하도록 처음부터 학습합니다.
- 장점: 일반적으로 동일 비트 수 대비 PTQ보다 높은 정확도를 달성하며, 특히 매우 낮은 정밀도에서 유리합니다.
- 단점: 추가적인 훈련 과정이 필요해 시간과 계산 비용이 더 많이 듭니다.
PTQ와 QAT 핵심 비교
| 특징 | 훈련 후 양자화 (PTQ) | 양자화 인식 훈련 (QAT) |
| 주요 목표 | 빠른 적용, 단순성 | 정확도 극대화 |
| 최종 정확도 | 양호하나, 낮은 비트에서 손실 가능성 존재 | 일반적으로 PTQ보다 높음, 특히 낮은 비트에서 유리 |
| 구현 복잡성 | 낮음 | 높음 (훈련/미세 조정 파이프라인 필요) |
| 필요 계산 비용 | 낮음 | 높음 (모델 재훈련 또는 미세 조정 필요) |
| 적합 사례 | 신속한 프로토타이핑, 정확도 손실 허용 시 | PTQ 결과 정확도 부족 시, 최대 정확도 확보 필요 시 |
LLM을 위한 고급 PTQ 기법: GPTQ와 AWQ
LLM의 거대한 크기로 인해, 효율적인 PTQ 기법에 대한 연구가 활발합니다.
GPTQ (Generative Pre-trained Transformer Quantization)

- 개념: GPTQ는 레이어 단위로 가중치를 양자화하되, 한 그룹의 가중치를 양자화할 때 발생하는 오차를 해당 레이어의 나머지 가중치들이 보상하도록 순차적으로 업데이트하는 방식입니다. 이를 통해 낮은 비트(예: 4비트)에서도 정확도 손실을 최소화합니다.
- 비유: 거대한 모자이크 벽화를 복원할 때, 한 부분의 타일 색상을 단순화하면서도 그로 인한 전체 그림의 변화를 인접 타일들의 색상을 미세 조정하여 최소화하는 정교한 장인과 같습니다.
- 효과: 매우 큰 모델도 상대적으로 짧은 시간에 3~4비트까지 가중치를 양자화하면서 정확도 손실을 줄일 수 있습니다. 메모리 사용량 감소와 추론 속도 향상을 기대할 수 있습니다.
AWQ (Activation-aware Weight Quantization)
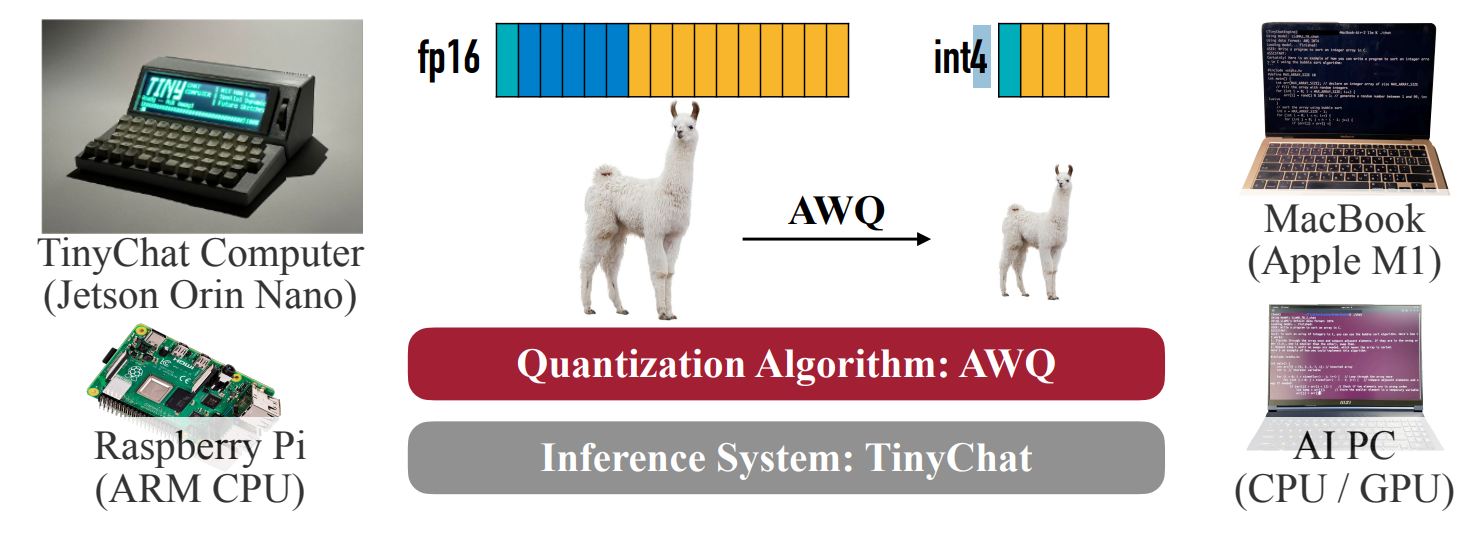
- 개념: AWQ는 모든 가중치가 모델 성능에 동일하게 중요하지 않다는 관찰에서 출발합니다. 활성화 값의 크기를 기준으로 중요한 가중치 채널(약 0.1%~1%)을 식별하고, 이 채널들은 양자화 시 발생하는 상대적 오차를 줄이도록 스케일링하여 보호합니다.
- 비유: 오케스트라 음악을 리마스터링할 때, 모든 악기 소리를 일률적으로 압축하는 대신, 가장 중요하고 두드러지는 악기(핵심 가중치)의 선명도를 우선적으로 보존하기 위해 해당 악기의 소리 크기를 전략적으로 조절하는 것과 유사합니다.
- 효과: 복잡한 재학습 없이 다양한 LLM에서 좋은 일반화 성능을 유지하며 속도 향상을 제공할 수 있다고 보고됩니다.
양자화의 영향: 성능, 크기, 정확도의 삼각관계
양자화는 모델의 여러 측면에 복합적으로 영향을 미칩니다.
- 모델 크기: 비트 수 감소에 따라 직접적으로 저장 공간이 줄어듭니다.
- 메모리 사용량: 추론 중 RAM 또는 VRAM 사용량이 감소하여, 제한된 하드웨어에서의 배포 가능성을 높입니다.
- 추론 속도: 데이터 이동량 감소와 저정밀도 연산 가속을 통해 향상될 수 있습니다.
- 정확도: 양자화는 본질적으로 효율성과 정확도 간의 트레이드오프 관계를 가집니다. QAT가 일반적으로 PTQ보다 정확도 보존에 유리하며, GPTQ, AWQ 같은 고급 기법은 매우 낮은 비트에서도 정확도 저하를 최소화하는 것을 목표로 합니다.
마무리하며
양자화는 대규모 언어 모델을 현실 세계의 다양한 애플리케이션에 적용 가능하게 만드는 핵심 기술로 자리매김했습니다. 모델의 크기와 연산 요구량을 줄임으로써, 스마트폰부터 IoT 기기까지 광범위한 하드웨어에서 AI 모델을 효율적으로 실행할 수 있는 길을 열어줍니다. 물론, 양자화 과정에서 발생하는 정확도 손실과 특정 모델 또는 언어에 대한 최적화 문제는 여전히 중요한 과제입니다. 하지만 PTQ, QAT의 지속적인 개선과 더불어 GPTQ, AWQ와 같은 고급 기법, 심지어 FP4와 같은 초저정밀도 양자화 연구는 이러한 한계를 극복하고 효율성과 정확도 사이의 최적점을 찾아가고 있습니다.
https://arxiv.org/abs/2210.17323
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Generative Pre-trained Transformer models, known as GPT or OPT, set themselves apart through breakthrough performance across complex language modelling tasks, but also by their extremely high computational and storage costs. Specifically, due to their mass
arxiv.org
https://arxiv.org/abs/2306.00978
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Large language models (LLMs) have transformed numerous AI applications. On-device LLM is becoming increasingly important: running LLMs locally on edge devices can reduce the cloud computing cost and protect users' privacy. However, the astronomical model s
arxiv.org
'Theory > FoundationModel Engineering' 카테고리의 다른 글
| AI 모델 배포: ONNX와 TensorRT로 날개를 달다 (0) | 2025.06.03 |
|---|---|
| FlashAttention: GPU 메모리 계층을 정복하여 어텐션 효율을 새롭게 정의하다 (0) | 2025.06.03 |
| LLM 추론 속도, 추측 디코딩으로 날개를 달다: 개념부터 작동 원리까지 (0) | 2025.06.03 |
| 초대형 AI 훈련, 메모리 걱정 뚝: ZeRO 3단계 완전 정복 가이드 (0) | 2025.05.28 |
| 파운데이션 모델 훈련, 병렬 처리로 한계를 넘어서다: 데이터, 텐서, 파이프라인 병렬 처리 완전 정복 (0) | 2025.05.28 |



