

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- transformer
- MHA
- gqa
- Multi-Head Attention
- PEFT
- self-attention
- Rope
- 트랜스포머
- MQA
- RLHF
- benchmark
- CoT
- LLM
- BLEU
- Rag
- rotary position embedding
- chain-of-thought
- Lora
- bad boy persona
- flashattention
- re-ranking
- fréchet inception distance
- attention
- Positional Encoding
- 창발적 오정렬
- reinforcement learning from human feedback
- misaligned persona
- FID
- clip
- catastrophic forgetting
- Today
- Total
AI Engineer의 '사부작' 공간
파운데이션 모델 훈련, 병렬 처리로 한계를 넘어서다: 데이터, 텐서, 파이프라인 병렬 처리 완전 정복 본문
파운데이션 모델 훈련, 병렬 처리로 한계를 넘어서다: 데이터, 텐서, 파이프라인 병렬 처리 완전 정복
ChoYongHo 2025. 5. 28. 08:15파운데이션 모델 훈련의 혁신: 병렬 처리로 한계를 넘어서다
인공지능(AI) 분야, 특히 자연어 처리(NLP)와 컴퓨터 비전 영역에서 파운데이션 모델의 등장은 가히 혁명적이었습니다. GPT, BERT와 같은 거대 언어 모델(LLM)부터 시작해 이미지 생성 모델에 이르기까지, 이들 모델은 이전에는 상상하기 어려웠던 수준의 성능을 보여주며 다양한 산업에 큰 영향을 미치고 있습니다. 하지만 이러한 강력한 성능 뒤에는 엄청난 규모의 모델 크기와 방대한 학습 데이터라는 과제가 숨어있습니다. "4개의 GPU로 분산 훈련을 시행하면, 1개의 GPU로 훈련하는 것보다 4배로 성능이 빨라질까?"라는 질문에 대한 답은 놀랍게도 "그렇다"입니다. 실제 테스트 결과 GPU 증가에 따라 이미지 분류의 경우 선형적으로 초당 이미지 처리 성능이 증가했습니다. 이는 올바른 병렬 처리 전략이 얼마나 강력한지를 보여주는 사례입니다. 마치 거대한 조각상을 혼자서 오랜 시간에 걸쳐 만드는 대신, 여러 조각가가 각자 부분을 맡아 동시에 작업하여 훨씬 빠르게 완성하는 것처럼, AI 모델 훈련에서도 분산 훈련(Distributed Training) 전략이 필수적입니다. 이번 글에서는 대규모 모델 훈련의 핵심 기술인 데이터 병렬 처리(Data Parallelism), 텐서 병렬 처리(Tensor Parallelism), 파이프라인 병렬 처리(Pipeline Parallelism)라는 세 가지 주요 병렬 처리 기법을 자세히 살펴보고, 이들을 더 쉽게 활용하도록 돕는 DeepSpeed와 PyTorch FSDP(Fully Sharded Data Parallel)와 같은 프레임워크에 대해서도 알아보겠습니다.
병렬 처리, 왜 필요하고 어떻게 작동할까요?
대규모 모델을 훈련할 때 마주하는 가장 큰 두 가지 문제는 메모리 부족과 훈련 시간입니다. 수십억, 수천억 개의 파라미터를 가진 모델은 단일 GPU의 메모리 용량을 훌쩍 뛰어넘습니다. 또한, 방대한 데이터셋으로 이러한 모델을 학습시키려면 엄청난 계산량이 필요하여 훈련 시간이 기하급수적으로 늘어납니다. 병렬 처리는 이러한 문제를 해결하기 위해 여러 개의 처리 장치(주로 GPU)를 함께 사용하여 모델 훈련 작업을 나누어 수행하는 기법입니다.
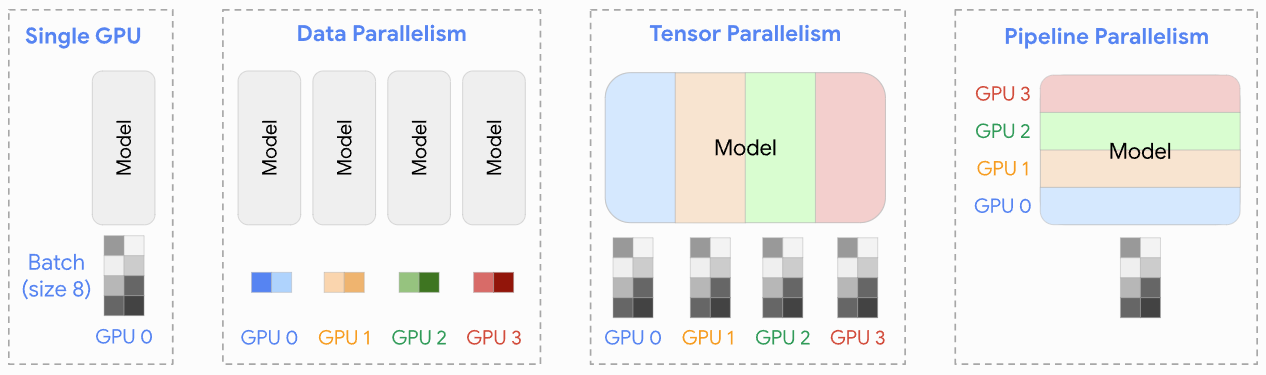
데이터 병렬 처리 (Data Parallelism, DP): 함께 일하지만 각자 다른 숙제를 풀어요!
개념: 데이터 병렬 처리는 가장 기본적인 병렬 처리 방식으로, 모델 전체를 여러 장치에 복제하고 각 장치가 전체 데이터 배치의 서로 다른 부분을 처리하여 학습 속도를 높이는 방식입니다.
작동 방식:
- 동일한 모델 복사본을 모든 GPU에 로드합니다.
- 전체 학습 데이터를 여러 개의 작은 미니배치(mini-batch)로 나눕니다.
- 각 GPU는 할당된 미니배치를 사용하여 모델의 순방향(forward pass) 및 역방향(backward pass) 연산을 수행하고, 이를 통해 그래디언트(gradient)를 계산합니다.
- 모든 GPU에서 계산된 그래디언트들을 하나로 모아 평균을 냅니다. (예: AllReduce 연산)
- 평균화된 그래디언트를 사용하여 모든 GPU의 모델 가중치를 동시에 업데이트합니다.
비유: 여러 명의 학생(GPU)에게 완전히 똑같은 문제집(모델)을 나눠주고, 각 학생에게 서로 다른 범위의 숙제(데이터 미니배치)를 내주는 것과 같습니다. 각자 숙제를 푼 후(그래디언트 계산), 선생님(중앙 조정자 또는 AllReduce 연산)이 모든 학생의 풀이 결과를 모아 평균적인 개선 방향을 찾고, 이를 다시 모든 학생의 문제집에 동일하게 반영(모델 업데이트)하는 것입니다.
사용 시점: 모델 자체는 단일 장치 메모리에 충분히 들어갈 수 있지만, 더 많은 데이터를 병렬로 처리하여 훈련 속도를 높이고 싶을 때 주로 사용됩니다.
성능 효과: 분산 훈련에서는 각 GPU 당 1개의 작업 프로세스(worker process)가 위치하여 각 GPU의 경사도 값을 서로 주고받고, 각자의 worker는 모아진 경사도들의 평균을 이용하여 모델을 변경합니다. 이로 인해 GPU 수에 비례하여 거의 선형적인 성능 향상을 기대할 수 있습니다.
텐서 병렬 처리 (Tensor Parallelism, TP): 거대한 블록, 나눠서 조립해요!
개념: 텐서 병렬 처리는 모델 내의 개별 연산, 특히 매우 큰 행렬 곱셈(예: 트랜스포머의 어텐션 계층이나 FFN 계층 내부) 자체를 여러 장치에 걸쳐 분할하여 수행하는 방식입니다.
작동 방식:
- 모델의 특정 계층(layer)에 있는 큰 가중치 행렬(텐서)을 여러 조각으로 나눕니다.
- 각 GPU는 이 나눠진 텐서 조각만을 저장하고 해당 부분의 연산을 수행합니다. 예를 들어, Y = XA라는 행렬 곱셈에서 가중치 행렬 A를 열 기준으로 분할(A = [A1, A2])하고, 각 GPU가 XA1, XA2를 계산합니다.
- 해당 계층의 순방향 및 역방향 계산 시, 부분 결과를 합치거나 필요한 정보를 교환하기 위해 장치 간 통신(예: AllReduce, AllGather)이 필요합니다.
비유: 매우 거대한 레고 블록(하나의 큰 텐서 연산)을 조립해야 한다고 상상해 보세요. 혼자서는 너무 크고 다루기 어렵기 때문에, 여러 명의 사람(GPU)이 각자 레고 블록의 다른 부분(분할된 텐서)을 맡아 동시에 조립하는 것입니다. 각자 맡은 부분을 조립한 후(부분 연산 수행), 서로의 결과를 합쳐(장치 간 통신) 최종 완성품(계층의 최종 출력)을 만드는 과정과 유사합니다.
사용 시점: 모델의 단일 계층조차 너무 커서 하나의 장치 메모리에 맞지 않을 때 사용됩니다. 데이터 병렬 처리만으로는 해결할 수 없는 매우 큰 모델에 효과적입니다.
파이프라인 병렬 처리 (Pipeline Parallelism, PP): 조립 라인처럼 순서대로, 하지만 동시에!
개념: 파이프라인 병렬 처리는 모델의 전체 계층들을 여러 개의 연속적인 단계(stage)로 나누고, 각 단계를 서로 다른 장치에 할당하여 마치 공장의 조립 라인처럼 데이터를 처리하는 방식입니다. 이는 레이어 간 병렬 처리라고도 하며 모델을 레이어별 덩어리로 분할하는 데 중점을 둡니다.
작동 방식:
- 모델의 계층들을 순서대로 여러 그룹(단계)으로 나눕니다. (예: 모델의 앞부분 몇 개 계층은 GPU 0, 다음 계층들은 GPU 1, ...)
- 데이터는 첫 번째 단계(GPU 0)부터 입력되어 순방향 계산을 거친 후, 그 결과(활성화 값)가 다음 단계(GPU 1)로 전달됩니다. 이 과정이 마지막 단계까지 반복됩니다.
- 역방향 계산 시에는 그래디언트가 역순으로 전달됩니다.
- 여러 데이터 미니배치를 동시에 파이프라인에 투입하여 "버블" (유휴 시간)을 최소화하고 GPU 활용도를 높입니다.
비유: 자동차 공장의 조립 라인을 생각해 볼 수 있습니다. 각 작업 스테이션(GPU)은 자동차(데이터)의 특정 부품(모델의 특정 계층 그룹)을 조립하는 역할을 합니다. 첫 번째 스테이션에서 차체 조립이 끝나면 다음 스테이션으로 넘겨 엔진을 장착하고, 또 다음 스테이션에서 바퀴를 다는 식입니다. 여러 대의 자동차가 동시에 각기 다른 조립 단계에 있을 수 있는 것처럼, 여러 미니배치가 파이프라인의 다른 단계에서 동시에 처리될 수 있습니다.
사용 시점: 모델 전체가 (텐서 병렬 처리를 사용하더라도) 단일 장치에 맞지 않을 때, 또는 순방향/역방향 계산 시 중간 계산 결과(활성화 값) 저장을 위한 메모리 부담을 줄이고 싶을 때 유용합니다.
이러한 병렬 처리 기법들은 각각의 장단점이 있으며, 실제 대규모 모델 훈련에서는 이들을 복합적으로 사용하는 하이브리드 방식이 일반적입니다. 예를 들어, 각 파이프라인 단계 내에서 데이터 병렬 처리나 텐서 병렬 처리를 추가로 적용할 수 있습니다.
복잡한 병렬 처리, 더 쉽게: DeepSpeed와 FSDP
위에서 설명한 병렬 처리 기법들을 직접 구현하고 관리하는 것은 매우 복잡하고 어려운 작업입니다. 다행히도 이러한 복잡성을 크게 줄여주는 강력한 프레임워크들이 등장했습니다. 대표적으로 DeepSpeed와 PyTorch FSDP(Fully Sharded Data Parallel)가 있습니다.
DeepSpeed: 대규모 모델 훈련을 위한 만능 도구상자
개념: DeepSpeed는 마이크로소프트에서 개발한 오픈소스 딥러닝 최적화 라이브러리로, 대규모 모델 훈련의 효율성과 속도를 크게 향상시키는 것을 목표로 합니다.
핵심 기술 - ZeRO (Zero Redundancy Optimizer): DeepSpeed의 핵심 기능 중 하나는 ZeRO입니다. ZeRO는 기존 데이터 병렬 처리에서 각 GPU가 모델 파라미터, 그래디언트, 옵티마이저 상태를 모두 복제하여 발생하는 메모리 중복 문제를 해결합니다. ZeRO는 다음과 같은 여러 단계로 작동합니다:
- ZeRO-Stage 1: 옵티마이저 상태(Optimizer States)를 여러 GPU에 분할 저장합니다.
- ZeRO-Stage 2: 그래디언트(Gradients)도 추가로 분할 저장합니다. 이를 통해 학습 가능한 모델 크기를 늘릴 수 있습니다.
- ZeRO-Stage 3: 모델 파라미터(Parameters)까지 분할 저장하여 메모리 효율을 극대화합니다.
- ZeRO-Offload: GPU 메모리가 부족할 경우, 옵티마이저 상태나 파라미터를 CPU 메모리로 오프로드하여 더 큰 모델을 훈련할 수 있게 합니다.
주요 기능 및 장점:
- 모델 파라미터, 그래디언트, 옵티마이저 상태를 분산하여 메모리 사용량을 크게 줄입니다.
- 텐서 병렬 처리, 파이프라인 병렬 처리와의 결합을 지원합니다.
- 혼합 정밀도 훈련, 효율적인 데이터 로딩 등 다양한 최적화 기능을 제공합니다.
- 매우 유연한 설정을 제공하여 사용자가 세밀하게 최적화할 수 있습니다.
예시: 1조 개(Trillion) 파라미터 규모의 모델 훈련과 같이 극도로 큰 모델을 훈련하는 데 사용될 수 있습니다.
PyTorch FSDP: PyTorch 네이티브의 강력한 메모리 최적화
개념: FSDP(Fully Sharded Data Parallel)는 PyTorch에 내장된 기능으로, 모델 파라미터, 그래디언트, 옵티마이저 상태를 여러 GPU에 걸쳐 분할(sharding)하여 메모리 사용량을 줄이는 데이터 병렬 처리 방식입니다. DeepSpeed의 ZeRO에서 영감을 받아 PyTorch 생태계에 맞게 재설계되었습니다.
작동 방식: FSDP는 모델을 더 작은 단위(FSDP unit)로 감싸고, 각 단위 내의 모든 파라미터를 평탄화한 후 분할합니다. 순방향 또는 역방향 계산 시, 해당 단위의 연산에 필요한 분할된 파라미터들만 모든 GPU로부터 모으고(all-gather), 연산이 끝나면 즉시 폐기하여 메모리를 절약합니다.
주요 기능 및 장점:
- PyTorch에 기본적으로 통합되어 있어 상대적으로 쉽게 사용할 수 있습니다.
- 지연 초기화(deferred initialization), 유연한 샤딩 전략, 통신과 계산 중첩, 프리페칭 등 고급 기술을 통해 효율성을 높입니다.
- 대규모 언어 모델 및 추천 모델 훈련에서 거의 선형적인 확장성을 보여줍니다.
고려 사항: FSDP를 효과적으로 사용하기 위해서는 모델 래핑 방식, 모델 가중치 초기화, 옵티마이저 설정, 혼합 정밀도 사용 등을 신중하게 고려해야 합니다.
DeepSpeed vs FSDP: 어떤 것을 선택해야 할까요?
두 프레임워크 모두 대규모 모델 훈련에 매우 유용하지만, 약간의 차이점이 있습니다:
| 특징 | DeepSpeed | FSDP (PyTorch Fully Sharded Data Parallel) |
| 메모리 최적화 | ZeRO Stage 0-3, 오프로드 등 세밀한 제어 | 동적 파라미터 샤딩, PyTorch 네이티브 |
| 프레임워크 통합 | 추가 라이브러리 설치 및 설정 필요 | PyTorch 자체 기능 |
| 복잡성 및 유연성 | 설정 옵션이 많아 유연하지만 다소 복잡 | 상대적으로 간결하지만 유연성은 다소 낮음 |
| 생태계 | PyTorch 외 다른 환경에서도 고려 가능 | 주로 PyTorch 프로젝트에 적합 |
- DeepSpeed가 유리한 경우: 매우 복잡한 모델 아키텍처에 대한 세밀한 최적화가 필요하거나, ZeRO의 고급 설정을 활용하고 싶을 때, 또는 PyTorch 외의 환경까지 고려할 때 더 적합할 수 있습니다.
- FSDP가 유리한 경우: 순수 PyTorch 기반 프로젝트에서 간편하게 분산 훈련을 적용하고 싶거나, PyTorch 네이티브 통합의 이점을 누리고 싶을 때 좋은 선택이 될 수 있습니다.
결국 어떤 프레임워크를 선택할지는 프로젝트의 특정 요구 사항, 사용 가능한 하드웨어, 팀의 전문 지식 등을 종합적으로 고려하여 결정해야 합니다.
마무리하며
파운데이션 모델의 시대는 우리에게 놀라운 가능성을 열어주었지만, 동시에 전례 없는 규모의 계산적 도전을 안겨주었습니다. 데이터 병렬 처리, 텐서 병렬 처리, 파이프라인 병렬 처리와 같은 분산 훈련 기법들은 이러한 도전을 극복하고 거대한 모델을 현실적으로 훈련할 수 있게 만드는 핵심 열쇠입니다. 실제로 "4개의 GPU로 분산 훈련을 시행하면 4배의 성능 향상"이 가능하다는 것이 실증적으로 입증되었듯이, 올바른 병렬 처리 전략은 단순히 이론적 개선을 넘어 실질적이고 측정 가능한 성과를 가져다줍니다. 더 나아가 DeepSpeed와 FSDP 같은 최적화 프레임워크들은 개발자들이 이러한 복잡한 기술을 더 쉽게 활용하여 AI 연구와 개발의 경계를 넓힐 수 있도록 돕고 있습니다.
Getting Started with Fully Sharded Data Parallel (FSDP2) — PyTorch Tutorials 2.7.0+cu126 documentation
Getting Started with Fully Sharded Data Parallel (FSDP2) Created On: Mar 17, 2022 | Last Updated: May 16, 2025 | Last Verified: Nov 05, 2024 Author: Wei Feng, Will Constable, Yifan Mao Note Check out the code in this tutorial from pytorch/examples. FSDP1 w
docs.pytorch.org
Latest News
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
www.deepspeed.ai
Parallelism methods
huggingface.co
'Theory > FoundationModel Engineering' 카테고리의 다른 글
| AI 모델 배포: ONNX와 TensorRT로 날개를 달다 (0) | 2025.06.03 |
|---|---|
| FlashAttention: GPU 메모리 계층을 정복하여 어텐션 효율을 새롭게 정의하다 (0) | 2025.06.03 |
| LLM 추론 속도, 추측 디코딩으로 날개를 달다: 개념부터 작동 원리까지 (0) | 2025.06.03 |
| AI 모델 다이어트 비법, 양자화: LLM 경량화, 어디까지 왔나? (0) | 2025.05.28 |
| 초대형 AI 훈련, 메모리 걱정 뚝: ZeRO 3단계 완전 정복 가이드 (0) | 2025.05.28 |



