
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 트랜스포머
- Positional Encoding
- BLEU
- extended thinking
- gqa
- CoT
- self-attention
- MQA
- Langchain
- context engineering
- catastrophic forgetting
- reinforcement learning from human feedback
- model context protocol
- chain-of-thought
- MHA
- attention
- rotary position embedding
- Multi-Head Attention
- SK AI SUMMIT 2025
- RLHF
- Engineering at Anthropic
- langgraph
- transformer
- re-ranking
- 토크나이저
- fréchet inception distance
- test-time scaling
- Embedding
- flashattention
- PEFT
- Today
- Total
AI Engineer 공간 "사부작 사부작"
AI 이미지 생성, 나만의 스타일을 입히다: 파인튜닝 기법 완전 정복 가이드 본문
AI 이미지 생성, 나만의 스타일을 입히다: 파인튜닝 기법 완전 정복 가이드
ChoYongHo 2025. 5. 27. 08:11AI 이미지 생성 모델 파인튜닝: 나만의 아티스트를 만드는 기술
마치 숙련된 화가가 자신만의 독특한 화풍을 개발해 나가듯이, 사전 훈련된 AI 이미지 생성 모델도 특정 스타일이나 주제에 맞게 조정할 수 있습니다. 이러한 과정을 '파인튜닝(Fine-tuning)'이라고 하는데, 이는 마치 잘 훈련된 요리사에게 특정 지역의 전통 요리법을 추가로 가르쳐 그 분야의 전문가로 만드는 것과 같습니다. 하지만 모든 요리사가 같은 방식으로 새로운 레시피를 배우지 않듯이, AI 모델을 파인튜닝하는 방법도 여러 가지가 있습니다. 각 방법은 맞춤 설정의 깊이, 필요한 데이터 양, 계산 자원 요구량 등에서 서로 다른 특징을 가집니다. 이번 글에서는 이미지 생성 모델의 주요 파인튜닝 기법들과 각각의 특징, 그리고 적용 시 주의해야 할 기술적 어려움들을 살펴보겠습니다.
주요 파인튜닝 기법들
▶ 전체(Full) 파인튜닝: 모델의 근본적 변화
개념: 모델의 전체 또는 대부분의 가중치를 새로운 목표 데이터셋으로 다시 훈련시키는 방식입니다.
특징:
- 장점: 모델의 동작을 근본적으로 크게 바꿀 수 있어 깊은 수준의 맞춤 설정이 가능합니다.
- 단점: 매우 많은 계산 자원(GPU 메모리, 시간)이 필요하고, 잘못하면 모델이 기존에 가지고 있던 방대한 지식이나 다양한 생성 능력을 잃어버릴 위험이 큽니다.
비유: 피아니스트가 클래식만 연주하던 것을 멈추고 재즈를 처음부터 완전히 새롭게 배우는 것과 같습니다. 시간과 노력이 많이 들지만 성공하면 완전히 다른 스타일의 연주가 가능해집니다.
▷ PEFT (Parameter-Efficient Fine-Tuning): 효율적인 맞춤 조정
PEFT는 모델의 대부분 가중치는 고정한 채, 일부 파라미터만 학습하여 자원 효율성을 높이는 방식입니다.
▷ LoRA (Low-Rank Adaptation)
개념: 기존 모델의 특정 계층(주로 어텐션 관련)에 저차원 행렬 형태의 작은 '어댑터'를 추가하고 이 어댑터만 학습합니다.
특징: 비교적 적은 자원으로 특정 스타일이나 미세 조정을 적용하는 데 효과적입니다.
예시: 애니메이션 스타일 이미지를 생성하고 싶을 때, 전체 모델을 다시 학습시킬 필요 없이 해당 스타일을 표현하는 작은 어댑터만 학습시켜 적용할 수 있습니다.
비유: 자동차 엔진 전체를 교체하는 대신, 특정 성능 향상을 위한 작은 튜닝 부품만 장착하는 것과 같습니다.
▷ 드림부스 (DreamBooth)
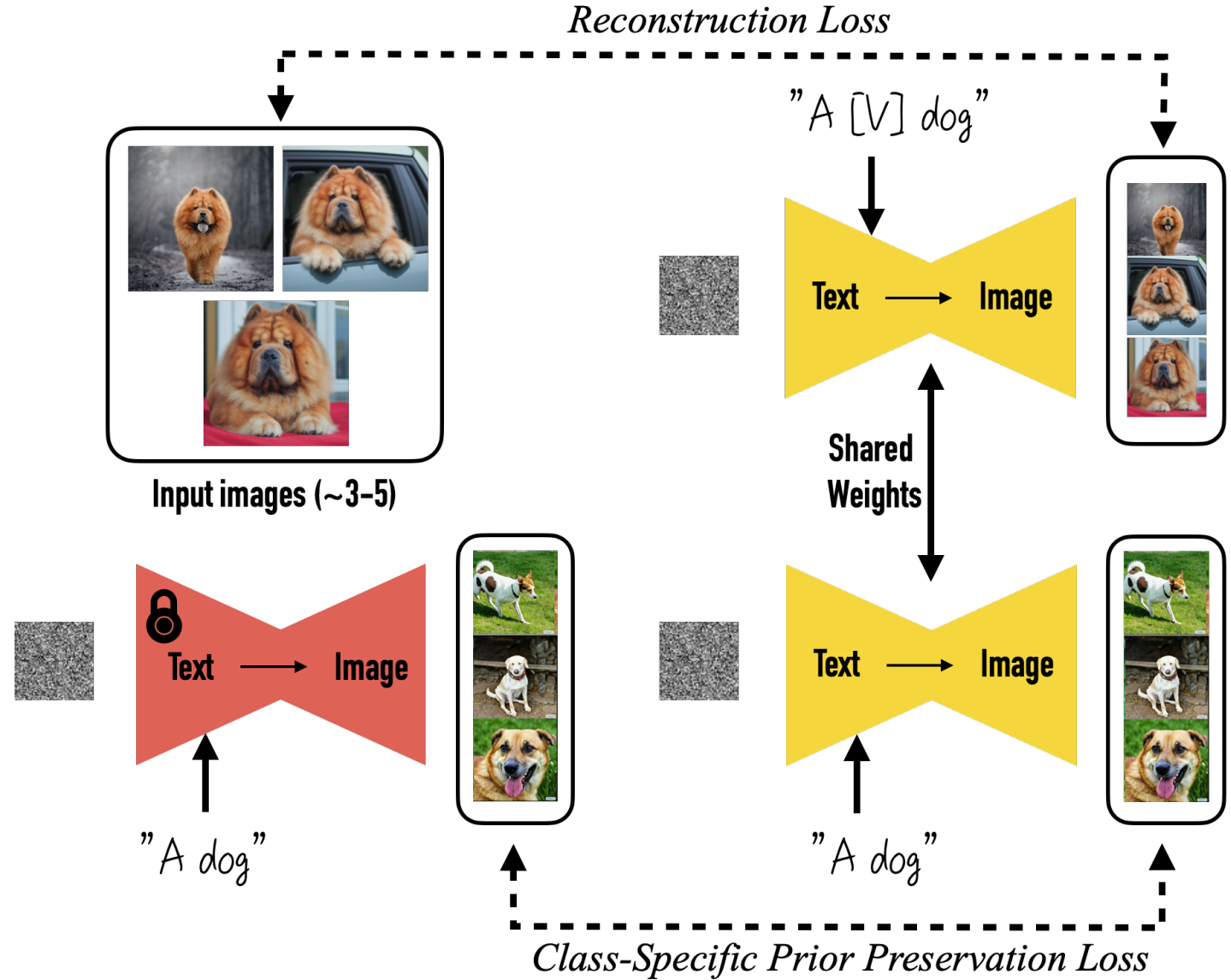
개념: 소수의 특정 대상 이미지(보통 3~5장)와 고유한 식별자 문자열을 사용하여 모델이 해당 대상을 매우 사실적으로 학습하도록 하는 기법입니다.
특징: 특정 인물, 애완동물, 사물 등을 매우 높은 충실도로 학습시켜 다양한 상황과 스타일로 생성할 수 있게 합니다.
예시: 자신의 애완견 사진 몇 장과 "sks dog"라는 특별한 키워드를 학습시켜, "sks dog in a spacesuit"와 같은 프롬프트로 다양한 상황의 애완견 이미지를 생성할 수 있습니다.
비유: 배우가 특정 역사적 인물의 사진 몇 장과 특징을 집중 학습하여 그 인물을 완벽하게 연기하는 것과 비슷합니다.
▷ 텍스추얼 인버전 (Textual Inversion)
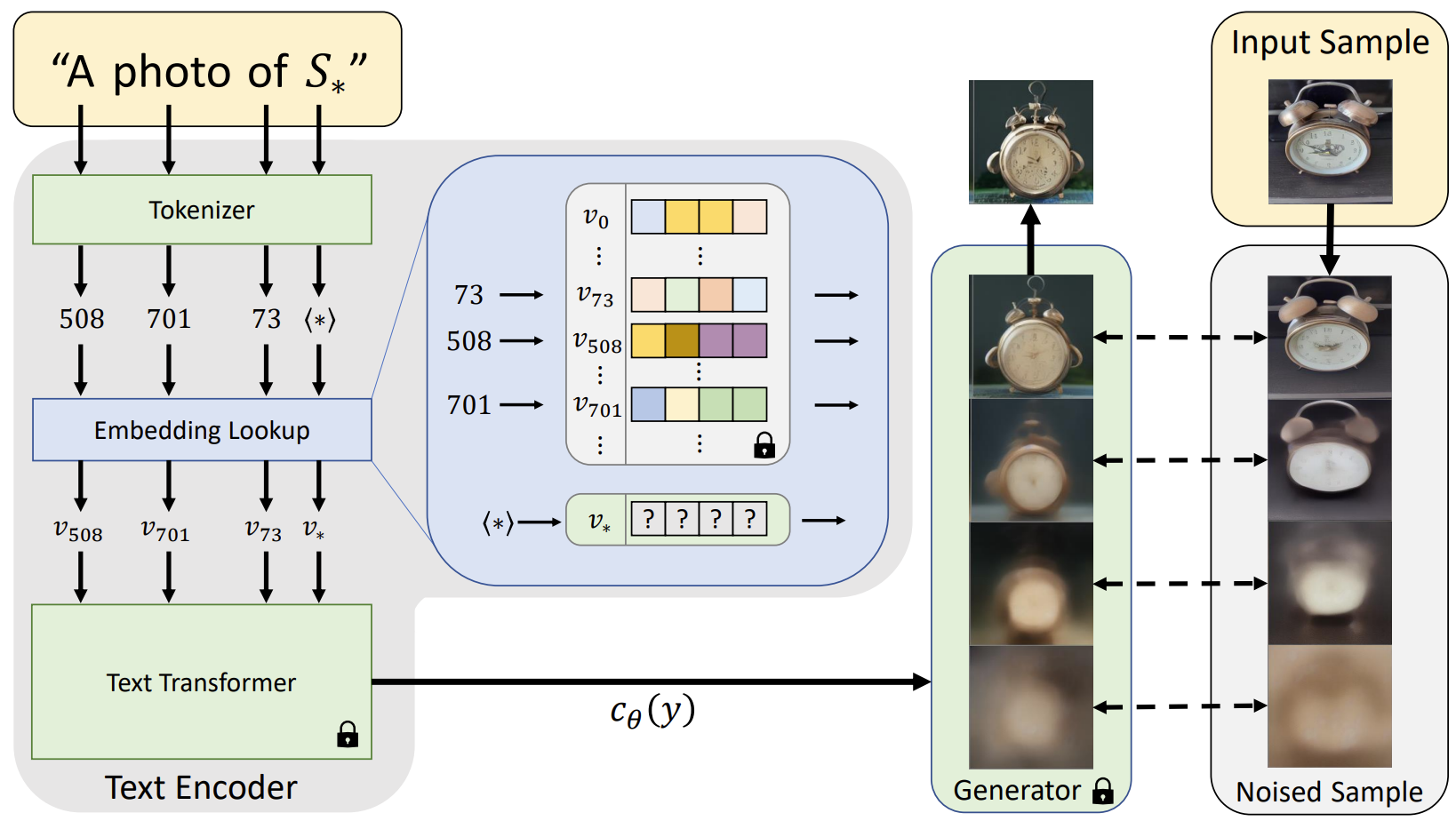
개념: 모델의 가중치는 전혀 변경하지 않고, 새로운 개념(스타일, 객체)을 나타내는 새로운 단어에 대한 임베딩 벡터만 학습합니다.
특징: 훈련이 매우 가볍고 빠르지만, DreamBooth만큼 특정 대상을 강하게 학습시키기는 어려울 수 있습니다.
예시: 특정 추상화 스타일의 이미지들로 "my_art_style"이라는 새로운 단어를 학습시킨 후, "a cat in my_art_style"로 해당 스타일이 적용된 고양이 이미지를 생성할 수 있습니다.
비유: 기존 사전은 그대로 두고, 새로운 단어 하나의 뜻만 추가로 정의하여 표현의 폭을 넓히는 것과 같습니다.
주요 기술적 어려움들
▶ 파국적 망각 (Catastrophic Forgetting)
개념: 새로운 스타일이나 개념을 학습하면서 모델이 이전에 학습했던 다양한 지식과 생성 능력을 잃어버리는 문제입니다.
비유: 새로운 외국어를 배우느라 모국어 실력이 떨어지는 상황과 비슷합니다.
영향: 특히 전체 파인튜닝 시 두드러질 수 있으며, 모델의 일반적인 생성 능력이 크게 저하될 수 있습니다.
▶ 과적합 (Overfitting)
개념: 파인튜닝 데이터에 모델이 지나치게 맞춰져, 생성 결과가 해당 데이터와 너무 유사하게만 나오거나 새로운 프롬프트에 대한 일반화 성능이 떨어지는 문제입니다.
결과: 결과물이 획일적이 되거나 다양성이 줄어들 수 있습니다.
비유: 시험 문제집만 반복해서 풀어 정답을 외워버린 학생이, 조금이라도 다른 유형의 문제가 나오면 풀지 못하는 상황과 같습니다.
▶ 균형 찾기
개념: 원하는 수준의 맞춤 설정을 달성하면서도 모델의 일반적인 생성 능력과 안정성을 유지하는 섬세한 균형점을 찾는 것이 중요합니다.
고려사항: 학습률, 훈련 데이터 양, 훈련 단계 수 등을 신중하게 조절해야 합니다.
비유: 요리에서 다양한 양념의 비율을 정교하게 맞춰야 하는 것처럼, 파인튜닝의 여러 요소들을 세심하게 조정해야 최적의 결과를 얻을 수 있습니다.
마무리하며
사전 훈련된 이미지 생성 모델의 파인튜닝은 AI를 나만의 특별한 아티스트로 만드는 강력한 도구입니다. 전체 파인튜닝부터 LoRA, 드림부스, 텍스추얼 인버전과 같은 효율적인 PEFT 기법까지, 각각의 방법은 서로 다른 장단점과 적용 시나리오를 가지고 있습니다. 파국적 망각, 과적합, 균형 조절과 같은 기술적 어려움들이 존재하지만, 이러한 도전을 이해하고 적절한 전략을 사용한다면 AI 이미지 생성의 무한한 가능성을 통해서 완벽한 AI 서비스를 만들 수 있습니다.
https://arxiv.org/abs/2208.01618
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and nove
arxiv.org
https://arxiv.org/abs/2208.12242
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference se
arxiv.org
'Theory > Image Generation-Diffusion' 카테고리의 다른 글
| ControlNet: 내 손안의 AI 아티스트, 상상하는 대로 이미지를 조종하다 (0) | 2025.05.23 |
|---|---|
| 확산 모델 샘플링 전략: 속도와 품질의 완벽한 균형을 찾아서 (0) | 2025.05.23 |
| 클래시파이어-프리 가이던스(Classifier-Free Guidance, CFG): 분류기 없이 더 똑똑해진 이미지 생성의 비밀 (0) | 2025.05.23 |
| 확산 트랜스포머(DiT): U-Net을 넘어선 이미지 생성 모델의 새로운 지평 (0) | 2025.05.22 |
| 노이즈에서 명작으로: 확산 모델과 잠재 확산 모델(Latent Diffusion Models, LDM) 파헤치기 (0) | 2025.05.21 |

