
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- transformer
- PEFT
- re-ranking
- 토크나이저
- Langchain
- catastrophic forgetting
- MHA
- CoT
- RLHF
- Embedding
- flashattention
- Multi-Head Attention
- rotary position embedding
- reinforcement learning from human feedback
- MQA
- test-time scaling
- fréchet inception distance
- model context protocol
- context engineering
- SK AI SUMMIT 2025
- chain-of-thought
- attention
- gqa
- BLEU
- langgraph
- Positional Encoding
- extended thinking
- self-attention
- Engineering at Anthropic
- 트랜스포머
- Today
- Total
AI Engineer 공간 "사부작 사부작"
확산 트랜스포머(DiT): U-Net을 넘어선 이미지 생성 모델의 새로운 지평 본문
확산 트랜스포머(DiT): U-Net을 넘어선 이미지 생성 모델의 새로운 지평
ChoYongHo 2025. 5. 22. 23:40확산 트랜스포머(DiT): U-Net을 넘어선 이미지 생성의 새로운 지평
인공지능 이미지 생성 기술은 마치 마법처럼 우리의 상상력을 시각적인 현실로 구현해내고 있습니다. 이러한 기술 발전의 핵심에는 '확산 모델(Diffusion Model)'이 있으며, 최근에는 이 확산 모델에 '트랜스포머(Transformer)' 아키텍처를 결합한 '확산 트랜스포머(Diffusion Transformer, DiT)'가 등장하여 이미지 생성 분야에 새로운 혁신의 바람을 불어넣고 있습니다. DiT는 기존 확산 모델에서 주로 사용되던 U-Net 아키텍처를 트랜스포머로 대체함으로써, 이전 모델들의 한계를 뛰어넘는 성능과 확장성을 보여주며 주목받고 있습니다. 그렇다면 확산 트랜스포머는 정확히 어떤 원리로 작동하며, 기존의 U-Net 기반 모델과는 어떤 점에서 차별화될까요? 또한, 이 새로운 아키텍처가 가져다주는 잠재적인 장점과 극복해야 할 단점은 무엇일까요? 본 글에서는 확산 트랜스포머의 핵심 개념부터 기존 모델과의 비교, 그리고 미래 가능성까지 심도 있게 살펴보겠습니다.
확산 모델과 트랜스포머: 혁신의 두 축
확산 트랜스포머를 이해하기 위해서는 먼저 두 가지 핵심 기술, 즉 확산 모델과 트랜스포머에 대한 이해가 필요합니다.
확산 모델 (Diffusion Model)
확산 모델은 이미지 생성 과정에서 점진적으로 노이즈를 제거하는 방식을 사용합니다. 마치 맑은 물에 잉크 한 방울을 떨어뜨리면 서서히 퍼져나가듯(순방향 과정, Forward Process), 원본 이미지에 단계적으로 미세한 노이즈를 추가하여 완전히 무작위적인 노이즈 상태로 만듭니다. 그리고 이 과정을 거꾸로 되돌려(역방향 과정, Reverse Process), 노이즈로부터 원본 이미지를 점진적으로 복원해내는 방법을 학습합니다. 모델은 각 단계에서 추가된 노이즈를 예측하고 제거하는 방법을 배우는 것입니다.
- 개념: 이미지에 의도적으로 노이즈를 추가했다가, 이 노이즈를 제거하는 방법을 학습하여 새로운 이미지를 생성하는 모델.
- 비유: 흐릿하게 만든 사진을 점차 선명하게 복원하는 과정을 학습하는 사진 편집 전문가와 같습니다. 처음에는 어떤 형체인지 알 수 없지만, 점차 노이즈를 제거하면서 숨겨진 이미지가 드러나는 것과 유사합니다.
- 잠재 확산 모델 (Latent Diffusion Model, LDM): 고해상도 이미지 픽셀 공간에서 직접 확산 모델을 학습하는 것은 계산 비용이 매우 큽니다. LDM은 이미지를 저차원의 잠재 공간(latent space)으로 압축한 뒤, 이 잠재 공간에서 확산 과정을 수행하여 계산 효율성을 크게 높인 모델입니다. DiT 역시 이러한 잠재 공간에서 작동하는 경우가 많습니다.
트랜스포머 (Transformer)
트랜스포머는 2017년 "Attention Is All You Need"라는 논문에서 처음 등장한 이후, 자연어 처리(NLP) 분야에 혁명적인 변화를 가져왔고, 최근에는 컴퓨터 비전 분야에서도 그 강력한 성능을 입증하고 있습니다. 트랜스포머의 핵심은 '셀프 어텐션(Self-Attention)' 메커니즘으로, 입력 데이터 내의 각 요소들이 서로 얼마나 연관되어 있는지를 한 번에 파악하여 전체적인 맥락을 이해합니다.
- 개념: 입력 시퀀스 내의 모든 요소 간의 관계를 동시에 고려하여 중요도를 판단하고, 이를 바탕으로 표현을 학습하는 신경망 아키텍처.
- 비유: 뛰어난 독서가가 책을 읽을 때, 특정 단어나 문장이 다른 어떤 부분과 중요한 연관성을 가지는지, 전체 내용에서 어떤 부분이 핵심적인지를 파악하며 밑줄을 치고 요약하는 과정과 유사합니다. 트랜스포머는 입력된 데이터 전체를 한 번에 보고 각 부분의 중요도와 상호 관계를 파악합니다.
확산 트랜스포머(DiT): 두 혁신의 만남
확산 트랜스포머(DiT)는 바로 이 강력한 두 기술, 확산 모델과 트랜스포머를 결합한 것입니다. 구체적으로, 확산 모델의 역방향 노이즈 제거 과정에서 전통적으로 사용되던 U-Net 아키텍처 대신 트랜스포머 아키텍처를 사용하는 모델을 의미합니다.
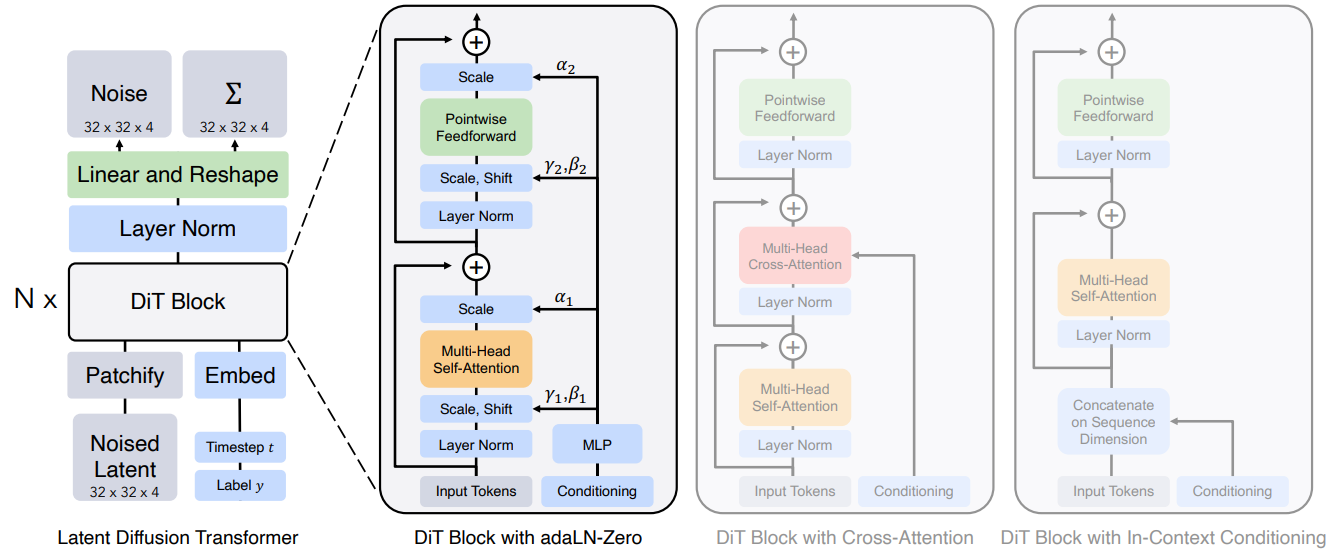
핵심 아이디어: DiT는 이미지를 여러 개의 작은 조각, '패치(patch)'로 나눕니다. 이 패치들은 마치 문장 속의 단어들처럼 시퀀스 데이터로 변환되어 트랜스포머의 입력으로 들어갑니다. 트랜스포머는 셀프 어텐션 메커니즘을 통해 이 패치들 간의 복잡한 관계를 학습하고, 각 패치에 포함된 노이즈를 효과적으로 예측하여 제거합니다. 이 과정에는 노이즈가 추가된 이미지 패치 시퀀스뿐만 아니라, 현재 노이즈 수준을 나타내는 '시간 단계 임베딩'이나 생성하려는 이미지에 대한 설명을 담은 '텍스트 임베딩'과 같은 조건부 정보도 함께 입력되어 활용될 수 있습니다.
비유: DiT는 고고학자가 수많은 유물 조각(이미지 패치)들을 발굴하여, 각 조각의 특징과 다른 조각들과의 관계(셀프 어텐션)를 면밀히 분석하여 거대한 고대 문명의 모습(원본 이미지)을 복원하는 과정에 비유할 수 있습니다. 이때, 발굴된 지층 정보(시간 단계 임베딩)나 역사 기록(텍스트 임베딩)은 복원 작업에 중요한 단서가 됩니다.
기존 U-Net 기반 확산 모델과의 차이점
DiT와 기존 U-Net 기반 확산 모델의 가장 큰 차이점은 핵심 네트워크 아키텍처와 그로 인한 특성입니다.
| 구분 | U-Net (컨볼루션 신경망) | 확산 트랜스포머 (DiT) |
| 주요 아키텍처 | 컨볼루션 계층, 다운/업샘플링, 스킵 연결 | 트랜스포머 블록 (셀프 어텐션, MLP) |
| 데이터 처리 | 이미지 전체를 계층적으로 처리, 지역적 특징 강조 |
이미지를 패치(Patch)로 분할 후 시퀀스로 처리, 전역적 관계 분석 |
| 귀납적 편향 | 강함 (지역성, 이동 불변성 등 이미지 특화 가정 내재) |
약함 (데이터로부터 학습, 위치 정보는 임베딩으로 제공) |
| 정보 수용 범위 | 지역적 → 전역적으로 점진 확장 | 초기부터 전역적 컨텍스트 파악 용이 |
| 장거리 의존성 | 상대적으로 어려움 (깊은 네트워크나 별도 모듈 필요) |
셀프 어텐션으로 효과적 포착 |
| 확장성 | 모델/데이터 증가 시 성능 향상에 한계 가능성 | 계산량 증가에 따른 꾸준한 성능 향상 |
| 주요 장점 | 이미지 특화된 효율적 학습, 상대적으로 적은 데이터로도 준수한 성능 |
뛰어난 확장성, 유연한 조건부 생성, 최신 대형 모델의 기반 |
| 주요 단점 | 확장성 한계, 복잡한 전역적 관계 파악에 불리 | 상대적으로 많은 데이터와 계산 자원 필요, 귀납적 편향 부족 가능성 |
U-Net: U-Net은 마치 정교한 필터 시스템과 같습니다. 이미지가 입력되면 다양한 크기의 필터(컨볼루션)를 거치면서 주요 특징이 추출되고(다운샘플링), 다시 이 특징들을 조합하여 원래 크기로 복원(업샘플링)합니다. 이 과정에서 초기 단계의 세밀한 정보와 후기 단계의 전체적인 정보를 '스킵 연결(skip connection)'이라는 통로로 직접 연결하여 정보 손실을 줄이고 정교한 복원을 돕습니다. 이미지의 지역적인 패턴을 파악하는 데 강점을 가집니다.
확산 트랜스포머(DiT): DiT는 마치 한 팀의 전문가들이 각자 이미지의 다른 조각(패치)을 분석한 후, 서로 긴밀하게 소통하며 전체 그림을 맞춰나가는 방식과 유사합니다. 각 전문가는 자신이 맡은 조각뿐만 아니라 다른 전문가들이 분석한 조각들의 정보까지 종합적으로 고려하여(셀프 어텐션), 자신의 조각에 숨겨진 원래 모습을 찾아냅니다. 이러한 방식은 이미지 내의 멀리 떨어진 요소들 간의 관계나 복잡한 맥락을 파악하는 데 더 유리할 수 있습니다.
확산 트랜스포머의 잠재적 장점
DiT는 트랜스포머 아키텍처의 고유한 특성 덕분에 여러 가지 매력적인 장점을 제공합니다.
- 뛰어난 확장성(Scalability): 트랜스포머의 가장 큰 강점 중 하나는 모델의 크기(파라미터 수, 깊이, 너비 등)나 학습 데이터의 양이 증가함에 따라 성능이 꾸준히 향상된다는 점입니다. DiT 역시 이러한 특성을 물려받아, 더 많은 계산 자원(Gflops)을 투입할수록 더 고품질의 이미지(낮은 FID 점수)를 생성하는 경향을 보입니다. 이는 더 크고 복잡한 모델을 통해 이전에는 불가능했던 수준의 이미지 생성을 가능하게 합니다.
- 기존 트랜스포머 생태계 활용: 이미 방대하게 구축된 트랜스포머 관련 연구, 최적화된 사전 훈련 기법, 다양한 라이브러리 등을 활용하여 모델 개발 및 개선 속도를 높일 수 있습니다.
- 유연한 조건부 생성: 트랜스포머는 다양한 종류의 조건(텍스트, 클래스 레이블, 다른 이미지 등)을 입력으로 함께 처리하는 데 유연합니다. 이를 통해 더욱 정교하고 다채로운 조건부 이미지 생성이 가능해집니다.
- 최신 모델의 기반 기술: DiT의 아이디어는 Stable Diffusion 3나 OpenAI의 비디오 생성 모델 SORA와 같은 최첨단 대형 생성 모델들의 핵심 기반 기술로 활용되고 있습니다. 이는 DiT의 중요성과 잠재력을 방증합니다.
예시 (확장성): 작은 오케스트라가 연주하는 단순한 멜로디에서 시작하여, 점차 악기의 종류와 연주자의 수를 늘려나가면서 더욱 풍부하고 웅장한 교향곡을 만들어내는 과정을 상상해 보세요. DiT의 확장성은 이와 유사하게, 모델의 규모가 커질수록 더욱 다채롭고 현실적인 이미지를 창조해낼 수 있는 능력에 비유할 수 있습니다.
확산 트랜스포머의 잠재적 단점 및 과제
모든 혁신적인 기술과 마찬가지로 DiT 역시 해결해야 할 과제와 잠재적인 단점을 가지고 있습니다.
- 귀납적 편향(Inductive Bias)의 상대적 부족: U-Net과 같은 컨볼루션 신경망(CNN)은 이미지의 지역성(인접 픽셀 간의 높은 연관성)이나 이동 불변성(객체의 위치가 변해도 동일 객체로 인식)과 같은 유용한 '사전 지식'을 구조적으로 가지고 있습니다. 이는 모델이 이미지의 특성을 더 빠르고 효율적으로 학습하도록 돕습니다. 반면, 트랜스포머는 이러한 사전 가정이 상대적으로 적어, 데이터로부터 모든 관계를 처음부터 학습해야 합니다. 이로 인해 때로는 더 많은 데이터와 계산 자원이 필요할 수 있습니다. (다만, DiT에서 이미지를 패치 단위로 처리하는 방식이나, 최근 연구에서 언급되는 어텐션 맵의 지역성 등이 이러한 단점을 일부 보완할 수 있습니다)
- 높은 계산 비용: 트랜스포머의 셀프 어텐션 연산은 입력 시퀀스(패치 수)의 길이에 제곱으로 비례하여 계산량이 증가하는 특성(O(N²))을 가집니다. 고해상도 이미지를 많은 패치로 나누어 처리할 경우 계산 비용이 급격히 증가할 수 있습니다. (하지만 잠재 확산 모델(LDM)처럼 저차원의 잠재 공간에서 작동함으로써 이러한 계산 부담을 크게 줄일 수 있습니다)
- 데이터 효율성: 일반적으로 트랜스포머는 CNN에 비해 방대한 양의 데이터를 필요로 하는 경향이 있습니다. 충분한 데이터가 뒷받침되지 않으면 최적의 성능을 발휘하기 어려울 수 있습니다.
- 훈련의 복잡성: DiT는 복잡한 노이즈 제거 과정을 학습해야 하므로, 모델을 훈련시키는 데 상당한 시간과 고성능 컴퓨팅 자원이 요구될 수 있습니다.
예시 (귀납적 편향): 숙련된 요리사(CNN)는 재료의 특성(지역성)이나 기본적인 조리법(이동 불변성)에 대한 사전 지식을 바탕으로 빠르고 효율적으로 맛있는 음식을 만듭니다. 반면, 이제 막 요리를 배우기 시작한 사람(트랜스포머)은 수많은 시행착오와 레시피 연구(데이터 학습)를 통해 자신만의 요리법을 터득해야 하는 것과 유사합니다. 물론, 충분한 경험이 쌓이면 기존의 틀을 깨는 창의적인 요리를 만들 수도 있습니다.
미래를 향한 진화: U-DiTs와 그 너머
DiT의 잠재력을 최대한 발휘하고 단점을 보완하기 위한 연구는 현재 활발히 진행 중입니다. 예를 들어, U-DiTs(U-shaped Diffusion Transformers)는 U-Net의 계층적인 인코더-디코더 구조와 스킵 연결의 장점을 트랜스포머에 접목하려는 시도입니다. 이를 통해 계산 효율성을 높이고 U-Net이 가진 유용한 귀납적 편향을 활용하여 성능을 더욱 향상시킬 수 있을 것으로 기대됩니다. 또한, 셀프 어텐션 메커니즘 자체를 개선하거나, 더 효율적인 방식으로 조건부 정보를 통합하는 연구, 그리고 모델 내부의 표현 학습을 가이드하는 자기 표현 정렬(Self-Representation Alignment, SRA)과 같은 기법들도 등장하고 있습니다.
마무리하며: 이미지 생성의 새로운 가능성을 열다
확산 트랜스포머(DiT)는 트랜스포머의 강력한 표현력과 뛰어난 확장성을 확산 모델에 성공적으로 결합함으로써, 이미지 생성 분야에 새로운 지평을 열었습니다. 기존 U-Net 기반 모델의 한계를 넘어서는 성능과 다양한 응용 가능성은 DiT가 앞으로 이미지 생성 기술의 발전을 이끌 핵심 동력이 될 것임을 시사합니다.
https://arxiv.org/abs/2212.09748
Scalable Diffusion Models with Transformers
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our D
arxiv.org
'Theory > Image Generation-Diffusion' 카테고리의 다른 글
| AI 이미지 생성, 나만의 스타일을 입히다: 파인튜닝 기법 완전 정복 가이드 (0) | 2025.05.27 |
|---|---|
| ControlNet: 내 손안의 AI 아티스트, 상상하는 대로 이미지를 조종하다 (0) | 2025.05.23 |
| 확산 모델 샘플링 전략: 속도와 품질의 완벽한 균형을 찾아서 (0) | 2025.05.23 |
| 클래시파이어-프리 가이던스(Classifier-Free Guidance, CFG): 분류기 없이 더 똑똑해진 이미지 생성의 비밀 (0) | 2025.05.23 |
| 노이즈에서 명작으로: 확산 모델과 잠재 확산 모델(Latent Diffusion Models, LDM) 파헤치기 (0) | 2025.05.21 |

