
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 토크나이저
- Multi-Head Attention
- Engineering at Anthropic
- self-attention
- PEFT
- reinforcement learning from human feedback
- 트랜스포머
- catastrophic forgetting
- Positional Encoding
- test-time scaling
- Langchain
- chain-of-thought
- fréchet inception distance
- transformer
- langgraph
- gqa
- flashattention
- rotary position embedding
- extended thinking
- RLHF
- attention
- Embedding
- BLEU
- SK AI SUMMIT 2025
- MHA
- context engineering
- MQA
- re-ranking
- CoT
- model context protocol
- Today
- Total
AI Engineer 공간 "사부작 사부작"
RAG 성능 평가: 신뢰할 수 있는 인공지능을 만드는 길 본문
RAG 성능 평가: LLM의 신뢰성과 잠재력을 극대화하는 핵심 전략
검색 증강 생성(Retrieval-Augmented Generation, RAG)은 대규모 언어 모델(LLM)이 외부 지식 소스를 활용하여 보다 정확하고 맥락에 맞는 답변을 생성하도록 하는 핵심 기술입니다. RAG 시스템은 사용자의 질의에 대응하여 관련 정보를 검색하고(Retrieval), 이를 기반으로 응답을 생성(Generation)하는 두 단계로 구성됩니다. 이러한 강력한 기능으로 인해 RAG는 복잡한 질의응답, 콘텐츠 생성, 연구 지원 등 다양한 분야에서 활용 가능성을 높이고 있지만, 그 성능을 체계적으로 평가하고 관리하는 것은 시스템의 신뢰성과 효용성을 보장하는 데 필수적입니다. 본 글에서는 RAG 성능 평가의 중요성과 핵심 차원, 그리고 주요 평가 지표들을 심층적으로 살펴보겠습니다.
RAG 성능 평가의 정의 및 중요성
RAG 성능 평가는 RAG 시스템이 사용자의 질의 의도를 얼마나 정확히 파악하고, 관련성 높은 정보를 효과적으로 검색하며, 이를 바탕으로 논리적이고 일관되며 신뢰할 수 있는 답변을 생성하는지를 종합적으로 측정하고 분석하는 과정입니다. 이 평가는 검색된 정보의 질과 생성된 답변의 품질 모두를 면밀히 검토합니다. RAG 시스템의 성능을 정확히 평가하는 것은 마치 숙련된 의사가 환자의 건강 상태를 다각도로 진단하는 것과 유사합니다. 정확한 진단(평가)이 있어야 적절한 처방(개선)을 통해 건강(시스템 성능)을 최적의 상태로 유지하고 향상할 수 있는 것처럼, RAG 평가도 시스템의 강점과 약점을 명확히 파악하여 그 잠재력을 최대한 발휘하도록 돕습니다.
RAG 성능 평가의 주요 차원 및 지표
RAG 시스템의 성능은 크게 검색(Retrieval) 단계, 생성(Generation) 단계, 그리고 이 둘을 통합적으로 평가하는 종합(End-to-End) 평가의 세 가지 차원으로 나누어 살펴볼 수 있습니다.
검색 단계 (Retrieval) 평가
검색 단계 평가는 RAG 시스템이 사용자의 질의에 대해 얼마나 관련성 높고 정확한 정보를 외부 데이터 소스에서 효율적으로 검색하는지를 측정합니다. 고품질의 검색 결과는 후속 생성 단계의 답변 품질에 직접적인 영향을 미칩니다. 이 단계는 마치 탐사보도 기자가 특정 사건에 대한 정보를 수집하는 과정과 같습니다. 기자는 방대한 자료 속에서 사건의 핵심과 직접적으로 관련된 증거와 증언을 정확하고 신속하게 찾아내야 합니다.
주요 평가지표:
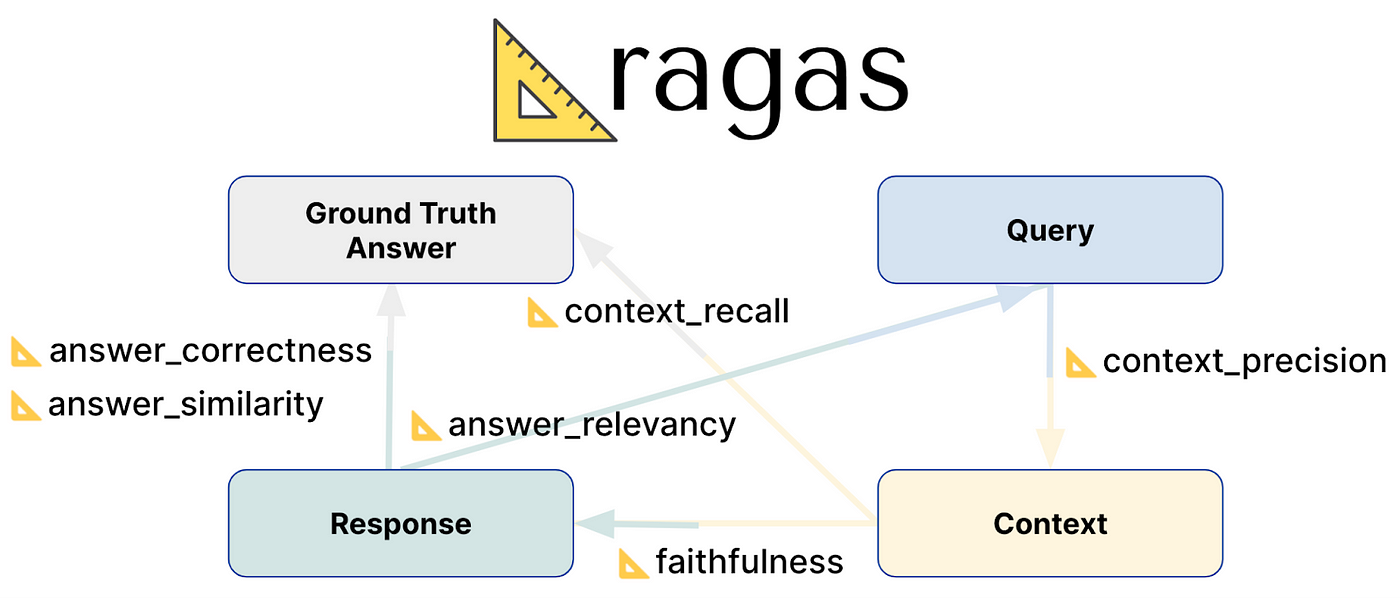
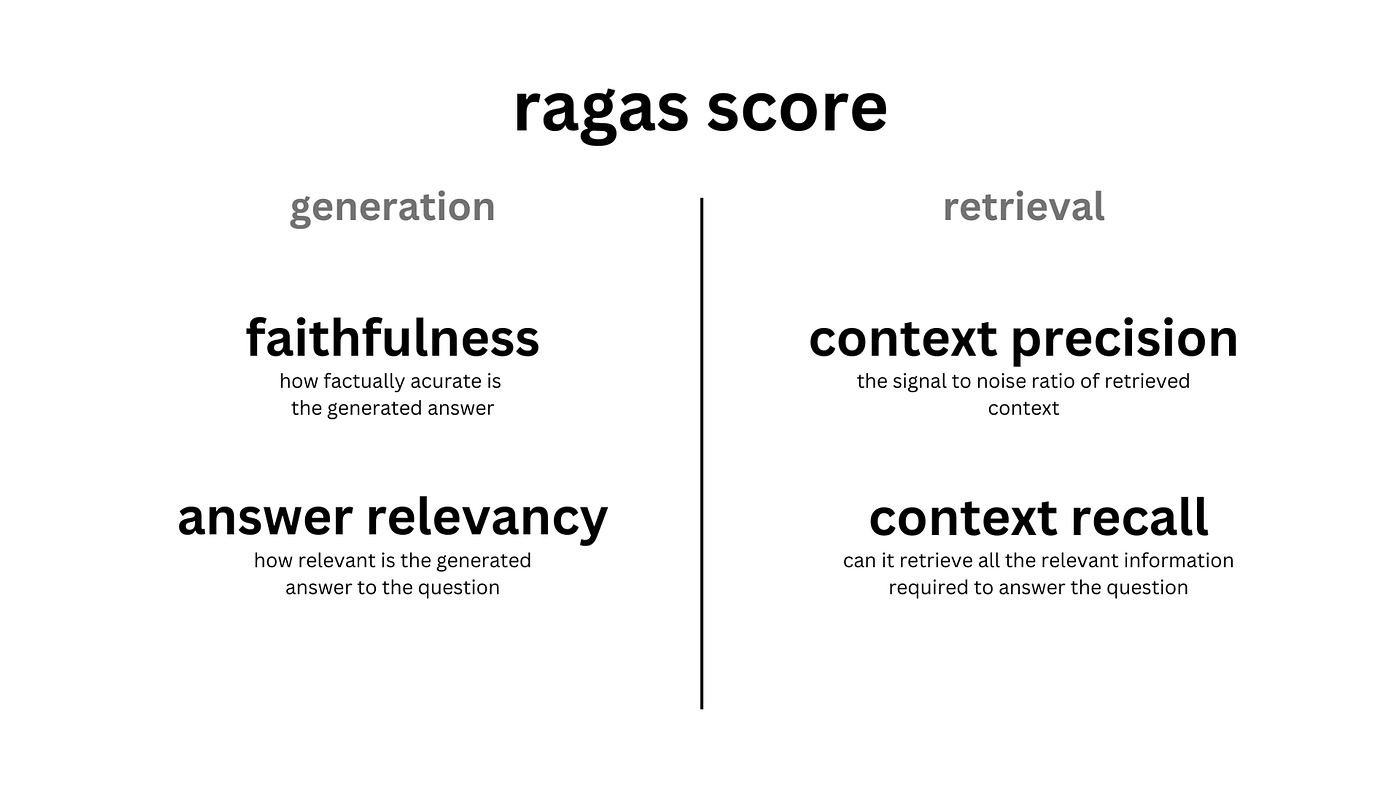
- 문맥 정밀도 (Context Precision): 검색된 컨텍스트(문서 또는 청크) 중에서 실제로 사용자의 질의에 답변하는 데 유용한 정보의 비율을 평가합니다.
- 비유: 어부가 그물을 던져 물고기를 잡을 때, 원하는 어종만 정확히 건져 올리고 불가사리나 해초 같은 불필요한 것들은 적게 포함된 상태와 유사합니다.
- 예시: "2023년 노벨 물리학상 수상자는 누구인가?"라는 질의에 시스템이 10개의 문서 조각을 검색했고, 그중 8개가 실제 수상자 및 관련 연구에 대한 유효한 정보였다면 문맥 정밀도는 80%입니다. 나머지 2개는 과거 노벨상 수상자 정보나 다른 분야의 과학상 정보일 수 있습니다.
- 문맥 재현율 (Context Recall): 질의에 답변하는 데 필요한 모든 관련 정보를 시스템이 얼마나 누락 없이 찾아냈는지를 평가합니다.
- 비유: 도서관 사서가 특정 주제에 대한 모든 중요 참고 도서를 빠짐없이 찾아 목록으로 제공하는 능력과 같습니다.
- 예시: 특정 질병의 치료법에 대한 질의 시, 관련된 핵심 임상 연구 논문이 총 5편 데이터베이스에 존재하는데 시스템이 그중 4편을 찾아냈다면 문맥 재현율은 80%입니다. 1편을 놓친 것이죠.
- MRR (Mean Reciprocal Rank): 여러 질의에 대해, 각 질의마다 첫 번째로 관련된 문서가 검색 결과 목록의 몇 번째 순위에 나타났는지의 역수(Reciprocal Rank)를 계산하고, 이 값들의 평균을 냅니다.
- 비유: 요리 레시피를 검색할 때, 가장 정확하고 인기 있는 레시피가 검색 결과 첫 페이지 상단에 바로 나타나는 것을 선호하는 것과 비슷합니다.
- 예시: 3개의 다른 질의에 대해, 첫 번째 관련 문서가 각각 1위, 2위, 3위에 나타났다면 역수 순위는 1, 1/2, 1/3이 되고, MRR은 (1 + 0.5 + 0.33) / 3 ≈ 0.61입니다.
- nDCG (normalized Discounted Cumulative Gain): 검색 결과의 순서뿐만 아니라, 각 문서의 관련성 등급(예: 매우 관련 높음, 관련 있음, 관련 낮음)까지 종합적으로 고려하여 평가하는 지표입니다.
- 비유: 영화 평점 사이트에서 단순히 영화 목록을 보여주는 것이 아니라, 평점이 높고 사용자 선호도에 맞는 영화를 상위에 배치하고, 덜 관련 있거나 평점이 낮은 영화는 하위에 배치하여 사용자 만족도를 높이는 것과 유사합니다.
- 예시: "최신 AI 기술 동향" 검색 시, 매우 중요한 최신 논문 A(관련도 3), 약간 관련된 블로그 B(관련도 2), 거의 관련 없는 과거 뉴스 C(관련도 1)가 검색되었다고 가정합니다. A, B, C 순으로 검색된 결과가 C, B, A 순으로 검색된 결과보다 nDCG 점수가 훨씬 높게 나옵니다.
생성 단계 (Generation) 평가
생성 단계 평가는 검색된 정보를 바탕으로 RAG 시스템이 얼마나 정확하고, 논리적이며, 일관성 있고, 사용자가 이해하기 쉬운 답변을 만들어내는지를 측정합니다. 이 단계는 마치 숙련된 번역가가 원문의 의미와 뉘앙스를 정확히 살리면서 목표 언어로 자연스럽게 옮기는 과정에 비유할 수 있습니다. 단순히 단어를 대체하는 것이 아니라, 맥락을 이해하고 적절한 표현을 창조해내야 합니다.
주요 평가지표:
- 충실성 (Faithfulness) / 근거성 (Groundedness): 생성된 답변이 제공된 컨텍스트 정보에 얼마나 충실하게 기반하고 있는지, 즉 사실을 왜곡하거나 없는 내용을 지어내지 않았는지를 평가합니다.
- 비유: 법정에서 증인이 자신이 직접 보고 들은 사실(제공된 컨텍스트)에만 입각하여 증언하고, 추측이나 개인적인 의견을 덧붙이지 않는 것과 같습니다.
- 예시: 검색된 컨텍스트에 "파리의 에펠탑은 1889년에 완공되었다."라는 내용이 있을 때, "에펠탑은 1889년 파리에 세워졌습니다."라고 답변하면 충실도가 높습니다. 만약 "에펠탑은 1889년 런던에 세워졌습니다." 또는 "에펠탑은 20세기에 완공되었습니다."라고 답변하면 충실도가 낮습니다.
- 답변 관련성 (Answer Relevancy): 생성된 답변이 사용자의 원래 질의 의도와 얼마나 밀접하게 관련되어 있는지를 평가합니다.
- 비유: 회의에서 발표자가 청중의 질문 핵심을 정확히 이해하고, 그 질문에 직접적으로 답하는 것과 같습니다. 동문서답을 피해야 합니다.
- 예시: "제주도 여행 시 추천할 만한 해변은 어디인가요?"라는 질의에 "제주도에는 협재 해수욕장, 중문 해수욕장 등이 유명합니다."라고 답변하면 관련성이 높습니다. 반면, "제주도는 아름다운 섬입니다." 또는 "제주도의 한라산 높이는 1950m입니다."와 같이 질의의 핵심에서 벗어난 답변은 관련성이 낮습니다.
- 답변 정확성 (Answer Correctness): 생성된 답변이 사전에 정의된 정답(ground truth) 또는 사실과 비교했을 때 얼마나 정확한지를 평가합니다.
- 비유: 수학 문제의 정답을 채점하는 것과 같이, 모델이 내놓은 답이 실제 참값과 일치하는지 확인합니다.
- 예시: "프랑스의 현재 대통령은 누구인가?"라는 질의에, 시스템이 "에마뉘엘 마크롱"이라고 정확히 답변하면 정답입니다.
- 답변 불가능성 평가 (Unanswerability Evaluation): 시스템이 답변할 수 없거나, 검색된 정보에 기반하여 답변하기에 부적절한 질의에 대해 "모르겠다" 또는 "제공된 정보로는 답변할 수 없다"와 같이 적절히 응답을 거절하는 능력을 평가합니다.
- 비유: 전문가에게 자신의 전문 분야가 아닌 질문을 했을 때, 솔직하게 "그 분야는 제 전문이 아니라 답변 드리기 어렵습니다."라고 말하는 것과 같습니다.
- 예시: "외계인의 평균 수명은 얼마인가?"와 같이 현재 알려진 사실이나 제공된 컨텍스트로는 답할 수 없는 질문에 대해, 시스템이 "현재까지 외계인의 존재나 평균 수명에 대한 과학적 근거는 없습니다." 또는 "제공된 정보로는 답변할 수 없습니다."라고 응답하는 경우입니다.
종합 (End-to-End) 평가
종합 평가는 RAG 시스템의 검색과 생성 단계가 얼마나 유기적으로 잘 작동하여, 궁극적으로 사용자에게 얼마나 유용하고 만족스러운 경험을 제공하는지를 전체적인 관점에서 평가합니다. 이는 오케스트라의 연주를 평가하는 것과 유사합니다. 각 악기(검색 모듈, 생성 모듈)의 연주 실력도 중요하지만, 모든 악기가 조화롭게 어우러져 하나의 아름다운 곡을 완성하는지(시스템 전체의 성능과 사용자 경험)가 최종적인 평가의 핵심입니다.
주요 평가지표:
- RAG 평점 (RAG Ratings / RAG Score): 모델이 생성한 답변의 전반적인 품질을 평가하는 점수입니다.
- 비유: 레스토랑 평론가가 음식의 맛, 재료의 신선도, 서비스, 분위기 등을 종합적으로 고려하여 별점을 매기는 것과 같습니다.
- 예시: 사용자가 RAG 시스템과 여러 차례 상호작용한 후, "이 시스템은 내 질문을 잘 이해하고, 관련성 높은 정보를 바탕으로 유용하고 정확한 답변을 신속하게 제공했다"고 판단하여 5점 만점에 4.5점을 부여하는 경우입니다.
- 응답 속도 (Latency): 사용자가 질의를 입력한 순간부터 시스템이 답변을 제공하기까지 걸리는 시간을 측정합니다.
- 비유: 웹사이트 로딩 속도와 같습니다. 콘텐츠가 아무리 훌륭해도 로딩이 너무 오래 걸리면 사용자는 페이지를 떠나버립니다.
- 예시: 복잡한 질의에 대해 시스템이 2초 이내에 답변을 생성하면 우수한 응답 속도라고 할 수 있지만, 10초 이상 걸린다면 개선이 필요합니다.
- 비용 (Cost): RAG 애플리케이션을 운영하는 데 소요되는 비용으로, API 호출 비용이나 토큰 소비량 등이 포함될 수 있습니다.
- 비유: 자동차의 연비와 같습니다. 성능이 좋더라도 유지 비용이 지나치게 높다면 실용성이 떨어질 수 있습니다.
- 예시: 특정 RAG 시스템이 질의당 평균 1000개의 토큰을 소비하고, LLM API 비용이 토큰당 특정 금액이라면, 월별 예상 운영 비용을 산출하여 경제성을 평가할 수 있습니다.
- 벤치마킹 (Benchmarking): 표준화된 데이터셋과 평가 프로토콜을 사용하여 다양한 RAG 시스템의 성능을 체계적으로 비교하고 정량적으로 평가합니다.
- 비유: 올림픽에서 선수들이 동일한 규칙과 조건 하에 기량을 겨루어 순위를 매기는 것과 같습니다.
- 예시: MS MARCO 데이터셋을 사용하여 개발 중인 RAG 시스템 A와 기존 상용 RAG 시스템 B의 MRR, nDCG 점수를 비교하여 상대적인 성능을 파악합니다.
RAG 평가 프레임워크 및 도구
최근 RAG 시스템 평가를 보다 체계적이고 자동화하기 위한 다양한 프레임워크와 도구들이 개발되고 있습니다. RAGAS, VERA, ARES, TruLens 등은 이러한 평가 과정을 지원하며, faithfulness, answer relevancy, context precision, context recall과 같은 지표들을 보다 효율적으로 측정할 수 있도록 돕습니다. 이 도구들은 마치 정밀 계측 장비처럼, RAG 시스템의 다양한 성능 측면을 객관적이고 일관되게 측정하여 개선 방향을 제시합니다.
마무리하며
RAG 시스템의 성능 평가는 일회성 작업이 아니라 시스템의 생명주기 동안 지속적으로 이루어져야 하는 반복적인 프로세스입니다. 검색 알고리즘의 개선, LLM 업데이트, 새로운 데이터 소스의 통합 등 시스템의 변화에 발맞춰 평가 방법론 또한 발전해야 합니다. 정교한 평가지표의 개발, 실제 사용 시나리오를 반영한 테스트 케이스 구축, 그리고 자동화된 평가 프레임워크의 활용은 RAG 시스템의 신뢰성을 높이고 그 잠재력을 최대한 발휘하게 하여 궁극적으로 사용자에게 더 나은 AI 경험을 제공하는 데 핵심적인 역할을 할 것입니다.
Ragas: Automated Evaluation of Retrieval Augmented Generation
We introduce Ragas (Retrieval Augmented Generation Assessment), a framework for reference-free evaluation of Retrieval Augmented Generation (RAG) pipelines. RAG systems are composed of a retrieval and an LLM based generation module, and provide LLMs with k
arxiv.org
https://arxiv.org/abs/2311.09476
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
Evaluating retrieval-augmented generation (RAG) systems traditionally relies on hand annotations for input queries, passages to retrieve, and responses to generate. We introduce ARES, an Automated RAG Evaluation System, for evaluating RAG systems along the
arxiv.org
https://arxiv.org/abs/2504.17137
MIRAGE: A Metric-Intensive Benchmark for Retrieval-Augmented Generation Evaluation
Retrieval-Augmented Generation (RAG) has gained prominence as an effective method for enhancing the generative capabilities of Large Language Models (LLMs) through the incorporation of external knowledge. However, the evaluation of RAG systems remains a ch
arxiv.org
https://medium.com/@danushidk507/evaluation-with-ragas-873a574b86a9
Evaluation with Ragas
Ragas is a framework designed to assess the performance of Retrieval-Augmented Generation (RAG) systems, which combine language models…
medium.com
'Theory > Retrieval-Augmented Generation' 카테고리의 다른 글
| Lost in the Middle: LLM은 왜 긴 글의 중간을 기억하지 못할까? (0) | 2025.06.12 |
|---|---|
| 고급 RAG 완전 정복: 쿼리 지능화, 검색 정교화, 반복 탐색으로 AI 답변의 격을 높이다! (0) | 2025.05.21 |
| 검색의 진화: 키워드부터 의미까지, 검색 기술의 삼위일체 (0) | 2025.05.20 |
| 검색 증강 생성(Retrieval-Augmented Generation, RAG): 똑똑한 LLM을 위한 실시간 외부 지식 연결고리 (0) | 2025.05.19 |



