

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- MQA
- transformer
- Positional Encoding
- 트랜스포머
- catastrophic forgetting
- Lora
- fréchet inception distance
- skip link
- self-attention
- gqa
- CoT
- rotary position embedding
- FID
- PEFT
- benchmark
- reinforcement learning from human feedback
- re-ranking
- Rag
- RLHF
- attention
- clip
- residual link
- swish gated linear unit
- chain-of-thought
- LLM
- Multi-Head Attention
- flashattention
- MHA
- Rope
- BLEU
- Today
- Total
AI Engineer의 '사부작' 공간
검색 증강 생성(Retrieval-Augmented Generation, RAG): 똑똑한 LLM을 위한 실시간 외부 지식 연결고리 본문
검색 증강 생성(Retrieval-Augmented Generation, RAG): 똑똑한 LLM을 위한 실시간 외부 지식 연결고리
ChoYongHo 2025. 5. 19. 22:06RAG: 똑똑한 LLM의 비밀 병기, RAG: 실시간 정보로 지능을 증강하다
최근 인공지능(AI) 분야, 특히 대규모 언어 모델(LLM)은 놀라운 발전을 거듭하며 우리의 삶에 깊숙이 들어오고 있습니다. 하지만 LLM도 만능은 아닙니다. 학습 데이터에 없는 최신 정보를 모르거나, 때로는 사실과 다른 내용을 그럴듯하게 지어내는 '환각(Hallucination)' 현상을 보이기도 하죠. 이러한 한계를 극복하기 위해 등장한 기술이 바로 검색 증강 생성(Retrieval-Augmented Generation, RAG)입니다.
RAG는 LLM이 답변을 생성하기 전에, 마치 똑똑한 조수가 옆에서 관련 자료를 찾아주듯, 외부 지식 소스에서 필요한 정보를 먼저 검색합니다. 그리고 이 검색된 정보를 바탕으로 LLM이 최종 답변을 생성하도록 하는 기술입니다. 이를 통해 LLM 답변의 정확성을 높이고, 최신 정보를 실시간으로 반영하며, 환각 현상을 줄이는 데 크게 기여합니다. 그렇다면 RAG 시스템은 어떻게 구성되어 있고, 어떤 마법을 부리는 걸까요? 그리고 언제 파인튜닝보다 RAG를 사용하는 것이 더 효과적일까요?
RAG 시스템의 핵심 삼총사: 지식 창고, 길잡이, 이야기꾼
RAG 시스템은 크게 세 가지 핵심 요소로 작동합니다. 이는 마치 방대한 도서관에서 사용자가 원하는 정보를 찾아 쉽고 정확하게 전달하는 과정과 유사하며, RAG 시스템 흐름도에서도 이러한 과정을 확인할 수 있습니다.
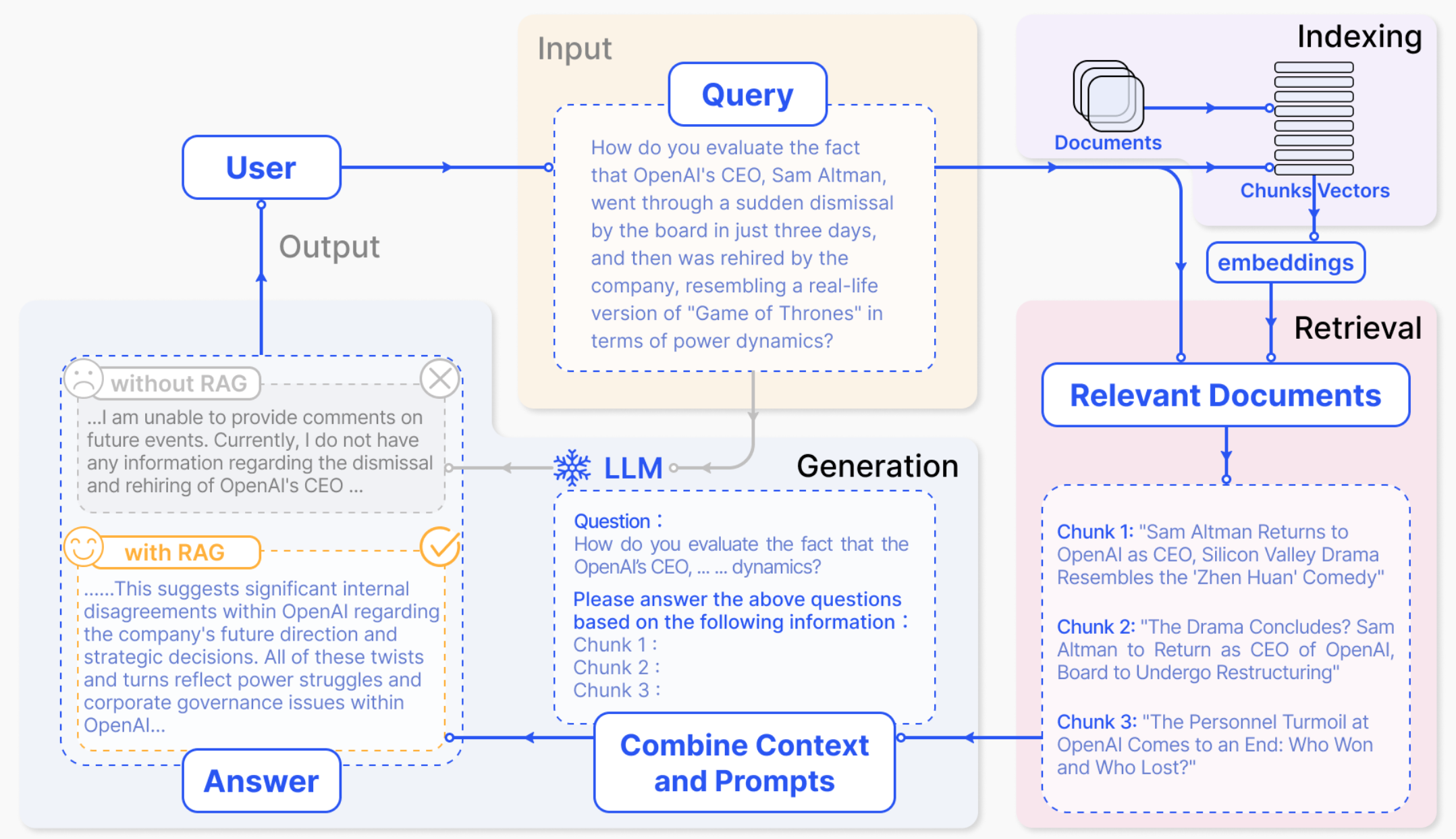
1. 지식 베이스 (Knowledge Base) 또는 문서 저장소 (Document Storage): 정보의 보고
- 개념: RAG 시스템이 답변을 생성하는 데 필요한 정보를 담고 있는 거대한 '지식 창고'입니다. 여기에는 웹 페이지, 뉴스 기사, 학술 논문, 기업 내부 문서, 데이터베이스 등 다양한 형태의 텍스트 데이터가 포함될 수 있습니다. 이 정보들은 효율적인 검색을 위해 미리 정제되고, 임베딩 모델을 통해 컴퓨터가 이해할 수 있는 벡터 형태로 변환되어 벡터 데이터베이스에 저장되기도 합니다.
- 비유: RAG 시스템의 '도서관 서가'라고 생각할 수 있습니다. 이 서가에는 세상의 온갖 지식이 분야별, 주제별로 잘 정리되어 꽂혀 있습니다. 정보가 최신 상태로 잘 관리될수록 양질의 답변을 기대할 수 있습니다.
- 예시: 의료 분야 RAG 시스템이라면 최신 의학 논문, 임상시험 결과, 질병 정보 데이터베이스 등이 지식 베이스를 구성할 수 있습니다.
2. 검색기 (Retriever) 또는 검색 모듈 (Retrieval Module): 질문의 핵심을 꿰뚫는 길잡이
- 개념: 사용자의 질문(쿼리)이 들어오면, 그 의도를 정확히 파악하여 지식 베이스에서 가장 관련성 높은 정보를 신속하게 찾아내는 역할을 합니다. 이를 위해 질문 자체를 분석하여 이해하기 쉬운 형태로 변환하는 '질의 인코더(Query Encoder)'와 변환된 질문을 바탕으로 실제 정보를 검색하는 '지식 검색기(Knowledge Retriever)' 등으로 구성될 수 있습니다. 검색된 정보는 관련도에 따라 순위가 매겨져 다음 단계로 전달됩니다.
- 비유: 도서관의 '베테랑 사서'와 같습니다. 사용자의 모호한 질문에도 핵심을 파악하고, 방대한 서가에서 가장 정확하고 도움이 될 만한 자료를 쏙쏙 골라주는 길잡이 역할을 합니다.
- 예시: 사용자가 "오늘 출시된 스마트폰 중 카메라 성능이 가장 좋은 모델은?"이라고 질문하면, 검색기는 '오늘 출시', '스마트폰', '카메라 성능', '최고 모델' 등의 키워드를 중심으로 지식 베이스에서 관련 제품 정보, 리뷰, 스펙 비교 자료 등을 찾아냅니다.
3. 생성기 (Generator) 또는 언어 모델 (Language Model): 정보를 엮어 답변을 만드는 이야기꾼
- 개념: 일반적으로 LLM이 이 역할을 수행하며, 사용자의 원래 질문과 검색기가 찾아낸 관련 정보를 함께 입력받아(이를 '강화된 컨텍스트'라고도 합니다), 이를 종합하여 자연스럽고 이해하기 쉬운 최종 답변을 생성합니다. 검색된 정보를 단순히 나열하는 것이 아니라, 질문의 맥락에 맞게 정보를 재구성하고 요약하여 새로운 답변을 만들어냅니다.
- 비유: 사서가 찾아준 다양한 자료들을 바탕으로, 사용자의 질문에 맞춰 일목요연하게 보고서를 작성하는 '능숙한 작가'나 '이야기꾼'에 비유할 수 있습니다.
- 예시: 검색기가 찾아준 최신 스마트폰 모델들의 카메라 스펙, 전문가 리뷰, 사용자 평가 등을 종합하여, 생성기는 "오늘 출시된 스마트폰 중 A 모델은 X 화소의 메인 카메라와 Y 기능의 망원 렌즈를 탑재하여 뛰어난 저조도 촬영 성능과 선명한 줌 기능을 제공하며, 사용자 평가도 매우 긍정적입니다."와 같이 구체적이고 유용한 답변을 생성합니다.
RAG vs. 파인튜닝: 언제 어떤 카드를 선택해야 할까?
LLM의 성능을 특정 작업에 맞게 끌어올리는 방법에는 RAG 외에도 '파인튜닝(Fine-tuning)'이 있습니다. 파인튜닝은 사전 학습된 모델을 특정 도메인의 데이터셋으로 추가 학습시켜 모델 내부의 지식이나 스타일을 조정하는 방식입니다. 그렇다면 언제 RAG를, 언제 파인튜닝을 선택하는 것이 현명할까요?
RAG가 빛을 발하는 순간들:
- 방대하고 역동적인 외부 지식을 실시간으로 활용해야 할 때:
- 개념: LLM의 파라미터 내에 모든 지식을 저장하기 어렵거나, 정보가 너무 자주 바뀌어 모델을 계속 재학습시키기 부담스러울 때 RAG는 외부 지식 베이스를 통해 항상 최신의, 그리고 특정 도메인에 특화된 정보를 활용할 수 있게 해줍니다.
- 비유: 주식 투자 전문가가 매일 변하는 시장 상황과 기업 정보를 즉시 반영하여 투자 조언을 해야 하는 경우와 같습니다. 매번 뇌를 '업데이트(파인튜닝)'하는 대신, 실시간 뉴스나 데이터베이스를 '참조(RAG)'하는 것이 훨씬 효율적입니다.
- 예시: 실시간으로 변하는 날씨 정보에 기반해 여행 계획을 추천하는 챗봇, 최신 법규나 판례를 반영해야 하는 법률 AI.
- 답변의 근거를 명확히 제시하고 신뢰도를 높이고 싶을 때:
- 개념: RAG는 검색된 문서를 답변의 근거로 제시할 수 있어, 사용자는 답변이 어디서 왔는지 출처를 확인할 수 있습니다. 이는 답변의 신뢰성을 크게 높여줍니다.
- 비유: 학생이 숙제를 할 때 참고한 책이나 논문을 명시하여 주장의 객관성을 높이는 것과 같습니다. RAG는 LLM에게 이러한 '참고 문헌 목록'을 제공해 줍니다.
- 예시: 의료 상담 챗봇이 특정 질병에 대한 정보를 제공하면서, 관련 의학 논문이나 공신력 있는 건강 정보 웹사이트를 출처로 함께 제시하는 경우.
- LLM의 '환각' 현상을 줄이고 사실 기반 답변을 원할 때:
- 개념: LLM이 잘 모르는 내용에 대해 그럴듯한 거짓 정보를 만들어내는 것을 '환각'이라고 합니다. RAG는 LLM이 추측에 의존하는 대신, 검색된 실제 데이터를 기반으로 답변하도록 유도하여 이러한 환각을 줄이는 데 효과적입니다.
- 비유: 중요한 시험에서 잘 모르는 문제가 나왔을 때, 찍는 대신 오픈북으로 교과서에서 정확한 답을 찾아 쓰는 것과 유사합니다. RAG는 LLM에게 '오픈북 시험'의 기회를 제공합니다.
- 예시: 역사적 사건에 대한 질문에 대해, LLM이 부정확한 연도나 인물 정보를 생성하는 대신, 역사 기록 데이터베이스를 검색하여 정확한 정보를 바탕으로 답변하는 경우.
- 특정 정보를 '잊지 않고' 정확하게 참조해야 할 때:
- 개념: 파인튜닝 과정에서 모델이 특정 세부 정보를 잊어버리거나 다른 정보와 혼동할 위험이 있지만, RAG는 외부 지식 베이스에서 직접 정보를 가져오므로 이러한 문제를 방지할 수 있습니다.
- 비유: 복잡한 기계의 수리 매뉴얼에 적힌 수많은 부품 번호 중 하나를 정확히 기억해야 할 때, 암기에 의존하기보다 필요할 때마다 매뉴얼을 찾아보는 것이 안전한 것과 같습니다.
- 예시: 고객 지원 챗봇이 수백 가지 제품 모델별 문제 해결 절차를 정확하게 안내해야 할 때, 각 모델의 매뉴얼을 지식 베이스로 구축하고 RAG를 통해 필요한 정보를 즉시 찾아 제공하는 경우.
파인튜닝이 더 적합한 경우:
반면, 파인튜닝은 모델의 근본적인 스타일, 어투, 특정 페르소나를 학습시키거나, 특정 기술이나 복잡한 행동 패턴을 모델 자체에 내재화시키고 싶을 때 더 효과적입니다. 예를 들어, 특정 작가의 문체를 모방하는 글쓰기 AI, 혹은 특정 브랜드의 정체성을 담은 고객 응대 챗봇을 만들고자 할 때 파인튜닝이 고려될 수 있습니다.
마무리하며
RAG는 LLM의 한계를 보완하고 그 활용 가능성을 한층 끌어올리는 강력한 기술입니다. 마치 똑똑한 LLM에게 실시간으로 외부 세계와 연결된 '지식의 창'을 열어주는 것과 같습니다. 물론 RAG 시스템을 효과적으로 구축하고 운영하기 위해서는 양질의 지식 베이스 구축, 효율적인 검색 전략, 그리고 생성 모델과의 유기적인 연동 등 고려해야 할 요소들이 많습니다. 하지만 RAG가 제시하는 방향성은 분명합니다. AI가 단순히 학습된 지식을 반복하는 것을 넘어, 능동적으로 외부 정보를 탐색하고 이를 바탕으로 더욱 정확하고 신뢰할 수 있는 결과물을 만들어내는 핵심 중 하나가 될 것입니다.
https://arxiv.org/abs/2312.10997
Retrieval-Augmented Generation for Large Language Models: A Survey
Large Language Models (LLMs) showcase impressive capabilities but encounter challenges like hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented Generation (RAG) has emerged as a promising solution by
arxiv.org
https://arxiv.org/abs/2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still lim
arxiv.org
https://arxiv.org/abs/2402.19473
Retrieval-Augmented Generation for AI-Generated Content: A Survey
Advancements in model algorithms, the growth of foundational models, and access to high-quality datasets have propelled the evolution of Artificial Intelligence Generated Content (AIGC). Despite its notable successes, AIGC still faces hurdles such as updat
arxiv.org
'Theory > Retrieval-Augmented Generation' 카테고리의 다른 글
| Lost in the Middle: LLM은 왜 긴 글의 중간을 기억하지 못할까? (0) | 2025.06.12 |
|---|---|
| 고급 RAG 완전 정복: 쿼리 지능화, 검색 정교화, 반복 탐색으로 AI 답변의 격을 높이다! (0) | 2025.05.21 |
| RAG 성능 평가: 신뢰할 수 있는 인공지능을 만드는 길 (0) | 2025.05.21 |
| 검색의 진화: 키워드부터 의미까지, 검색 기술의 삼위일체 (0) | 2025.05.20 |



