
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- self-attention
- BLEU
- MQA
- CoT
- MHA
- transformer
- extended thinking
- 트랜스포머
- flashattention
- PEFT
- langgraph
- chain-of-thought
- context engineering
- Langchain
- 토크나이저
- rotary position embedding
- catastrophic forgetting
- Multi-Head Attention
- model context protocol
- reinforcement learning from human feedback
- gqa
- RLHF
- test-time scaling
- SK AI SUMMIT 2025
- Engineering at Anthropic
- attention
- re-ranking
- Positional Encoding
- Embedding
- fréchet inception distance
Archives
- Today
- Total
AI Engineer 공간 "사부작 사부작"
[SK AI SUMMIT 2025] AI의 미래를 경험하다 - Day 2 본문
728x90
안녕하세요. 오늘은 SK SUMMIT 2025 Day 2에 대한 세션 중에서, 제가 AI서비스를 연구 및 개발하는데 있어서 유의미한 내용의 세션을 몇개 소개해드리려고 합니다. AI Model 세션으로 총 5개의 세션입니다. 각 세션들의 내용을 간단히 살펴보도록 하겠습니다.

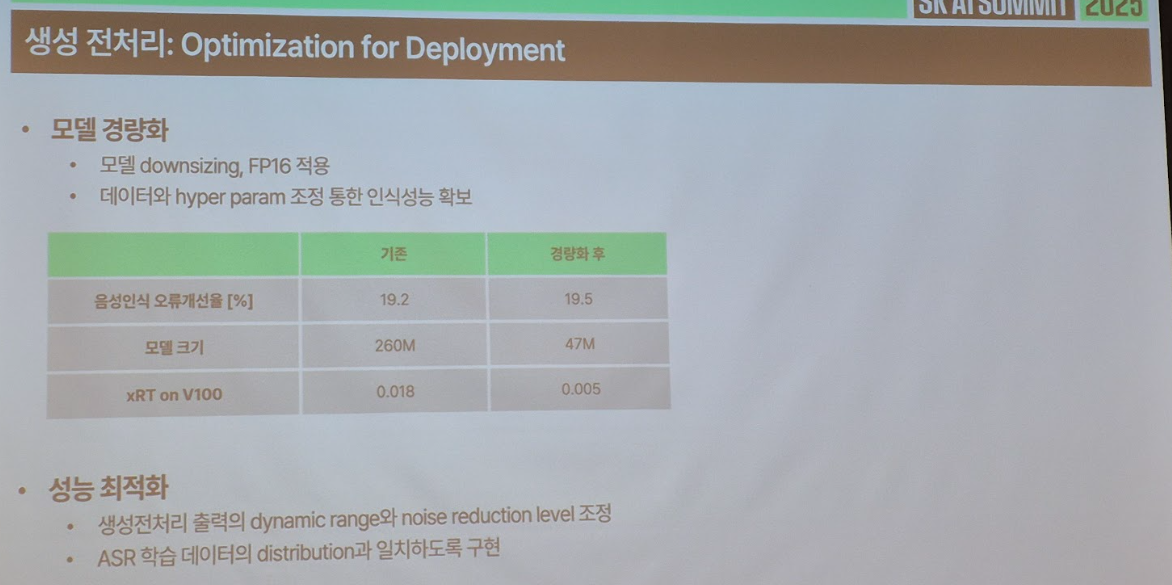
■ 회의·강의 환경에서도 정확하게 : 에이닷노트 음성인식 성능을 끌어올린 Generative AI 전처리 기술 소개
- 송명석(SK텔레콤 Manager)
- 한줄 요약: Diffusion Model 기반의 음성 전처리 기술로, 학습용 데이터를 고품질로 생성하는 기술
- 시사점: 기존 Clean Speech 데이터셋에 다양한 Augmentation을 적용하고, Consistency Model을 통해 안정적으로 수렴하도록 설계함으로써 실제 환경 소음에서도 높은 성능의 ASR(Automatic Speech Recognition)을 가능하게 함.
- 내용: AI 기술이 대중화되면서 음성인식은 단순한 음성 명령 제어를 넘어서 회의록 자동 생성, 강의 녹취 등 생산성 도구로 빠르게 확장되고 있습니다. 하지만 실환경의 녹음은 소음·반향·잡음이 뒤섞여 있어 기존 ASR 기술만으로는 충분한 정확도를 확보하기 어려웠습니다. 이에 Generative AI를 활용한 음성 전처리 기술을 도입하여 ASR 성능을 획기적으로 개선했습니다. Diffusion Model 기반 생성 기술을 통해 잡음과 반향을 제거하고 깨끗한 음성 신호를 복원함으로써, 기존 ASR 모델의 한계를 극복하고 실제 서비스 품질을 한 단계 끌어올린 것입니다.




■ AI 기반 영상 이해·생성 기술의 서비스 적용기
- 최지영(SK텔레콤 Manager)
- 한줄 요약: 오픈소스 OCR 모델의 한계를 극복하기 위해 자체 Vision 모델을 학습·튜닝하여 한국어 및 특정 도메인 문서 인식 성능을 대폭 향상
- 시사점: 기존 오픈소스 OCR 및 API 기반 서비스는 한국어·특정 산업 문서(표·차트·서식 등)에 대한 이해도가 낮다는 한계가 존재. 이에 Vision 기반 자체 모델을 학습 및 정교하게 튜닝함으로써 산업별 문서를 정확히 파싱하고, 서비스 품질을 크게 개선
- 내용: AI 기술이 빠르게 발전하고 있지만, 실제 서비스 환경에서 안정적인 성능을 제공하려면 모델 선정, 목적에 맞는 파인튜닝, 그리고 전처리·후처리를 포함한 품질 관리가 필수적입니다. 영상 이해 파트에서는 데이터 확보 전략, OCR 엔진 고도화, SFT·KTO·DPO·RLVR 등 다양한 학습 기법을 활용한 성능 향상 사례를 다룹니다. 영상 생성 영역에서는 생성 영상을 활용한 B2C 콘텐츠 강화 사례와, 안정적인 품질·속도를 동시에 달성하기 위한 모델 최적화 방안을 소개합니다.







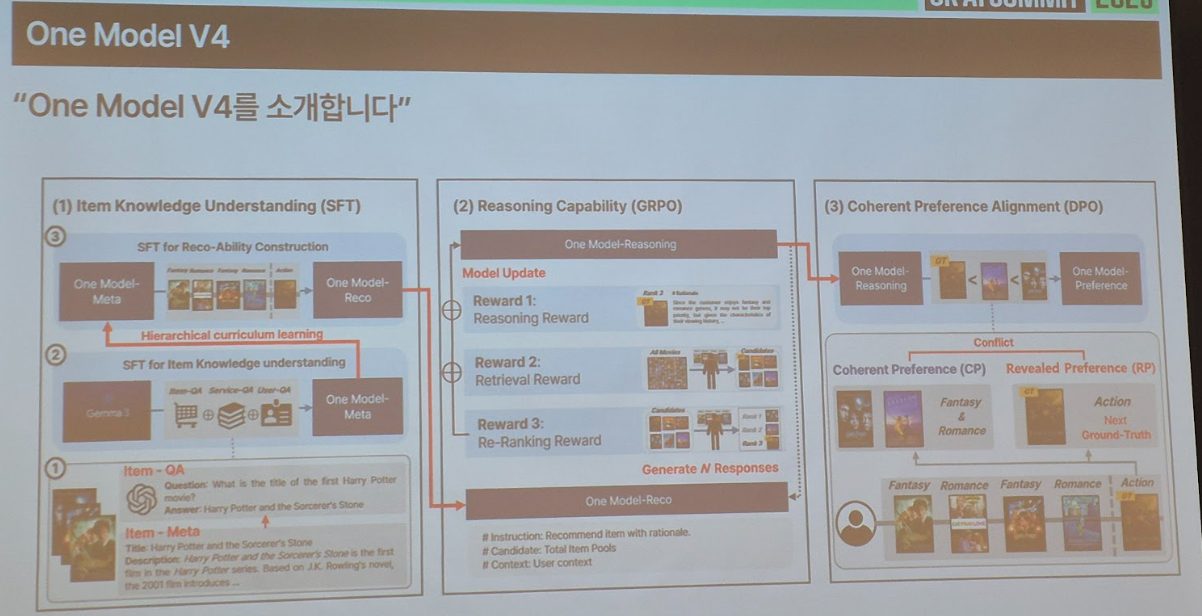
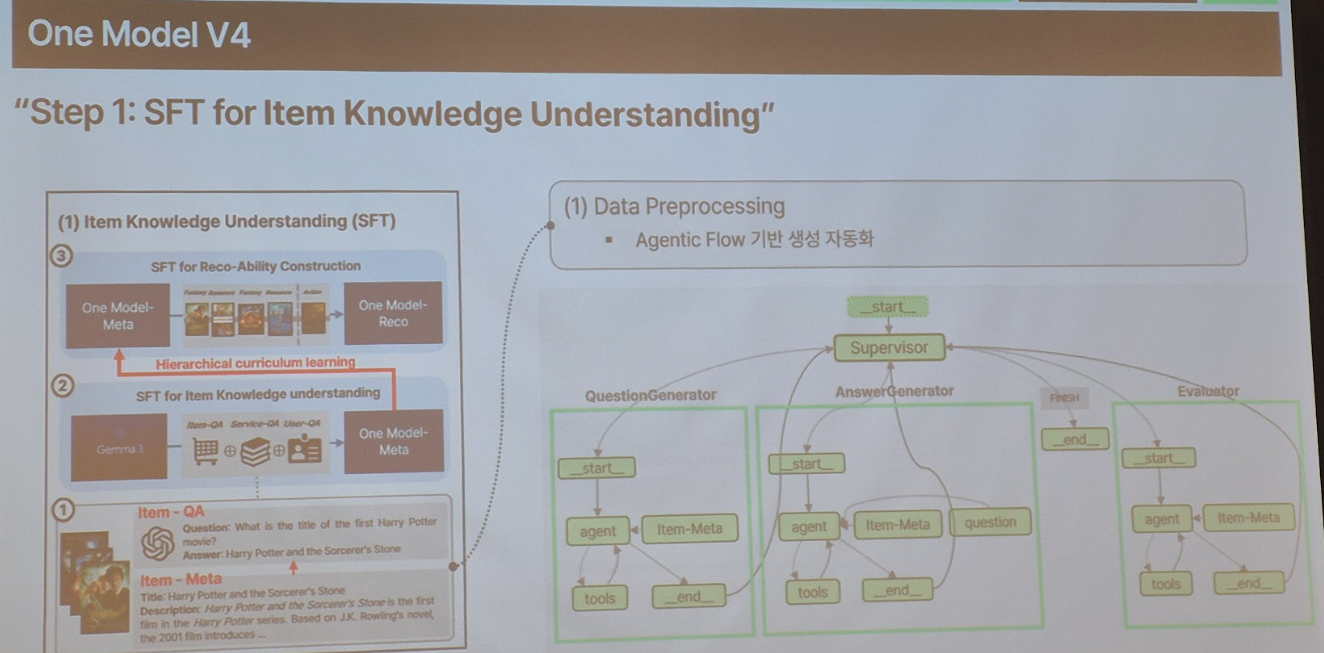
■ LLM이 추천을 만나면? SKT의 LLM 기반 추천 시스템 개발기
- 김태(SK텔레콤 Manager)
- 한줄 요약: 여러 서비스 도메인의 추천 문제를 하나의 ‘One Model v4’ LLM으로 해결하기 위해 통합 모델을 학습·튜닝
- 시사점: 도메인별 추천 모델의 한계를 극복하기 위해 SFT 및 RL 기반의 파인튜닝을 수행하고, 데이터 전처리 과정에 멀티에이전트 아키텍처(Supervisor)를 도입하여 효율성을 극대화. 이를 통해 다양한 서비스에 일관된 고성능 추천을 제공할 수 있는 통합 모델을 구축
- 내용: 고객 행동 데이터를 바탕으로 요금제, T우주 구독, 멤버십, Tworld AI, A.Dot, Tdeal 등 다양한 서비스에서 개인화 추천을 운영. 하지만 서비스별로 별도 추천 엔진을 운영하다 보니 도메인 간 시너지가 부족하고, 신규 서비스마다 새 엔진을 개발해야 하는 비효율이 발생. 이를 해결하기 위해 2023년부터 전사 통합 추천 프로젝트 ‘One-Model’을 추진하였고, 올해 개발된 v4는 생성형 LLM 기반 추천 모델로 확장되었습니다. 이제는 단순한 아이템 추천을 넘어 추천 사유, 마케팅 메시지, 연관 상품까지 자연스러운 문장으로 제공하는 ‘설득형 추천’이 가능해졌습니다.



■ 오픈소스, 강화학습을 만나다 : Helpy의 특화 AI 모델 개발 전략
- 김수인(Elice CRO & Co-Founder)
- 한줄 요약:오픈소스 Qwen2.5를 기반으로 지도학습(SFT)과 강화학습(RL)을 적용해 특정 비즈니스 도메인 문제를 해
- 시사점: 지도학습(SFT)과 강화학습(RL)을 통해 특정 도메인(예: 국사)에서 매우 높은 정확도를 내는 특화 모델을 개발함. 다만 특화 모델 특성상 일반화 성능은 다소 낮을 수 있음. 또한 생성 모델과 평가 모델을 에이전트 구조로 연결해 “항상 정확한 답변만 반환”하도록 설계했으며, 한국 문서 및 사내 문서(표·차트)를 정확하게 파싱하기 위해 VLM(Helpy Struct)도 커스터마이징하여 산업에 적용함. 현재 트렌드는 ‘도메인 특화 모델을 활용한 실전 비즈니스 문제 해결’임을 시사.
- 내용: 오픈소스 대형 모델들이 널리 활용되는 시대이지만, 특정 도메인에 특화된 고신뢰 모델을 개발하는 일은 여전히 어려운 과제입니다. 특히 신뢰할 수 있는 데이터가 부족한 분야에서는 성능 확보가 더욱 어렵습니다. ‘Helpy’ 개발 과정에서는 이러한 한계를 강화학습으로 극복했습니다. Helpy Edu는 국사편찬위원회 데이터를 기반으로 학습된 교육용 챗봇으로, 제한된 데이터 환경에서도 강화학습을 통해 사실 오류 없이 안정적이고 정확한 답변을 생성하도록 개선되었습니다. 또한 Vision-Language 모델인 Helpy Struct를 통해 이미지 속 표·문서를 정확하게 구조화하여 실사용에 적용한 사례








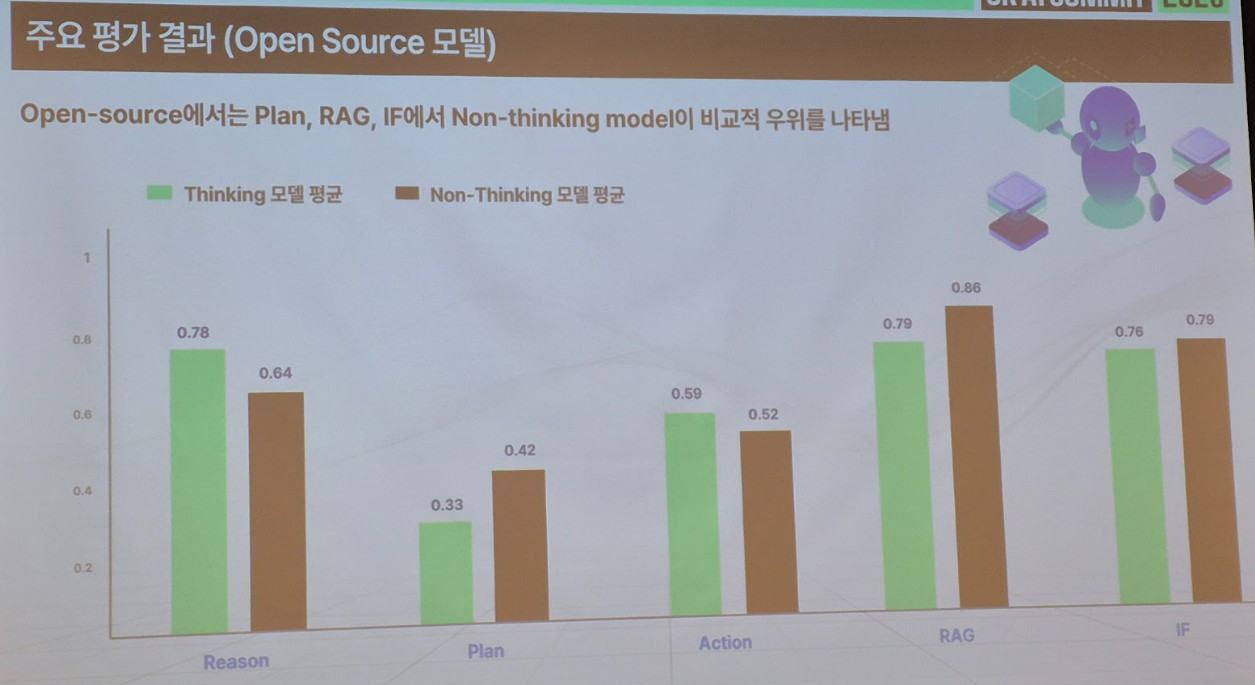
■ TelAgentBench – Telco 도메인 사례로 보는 에이전트 성능 평가
- 이선우(SK텔레콤 팀장)
- 한줄 요약:통신 도메인 특성을 반영해 에이전트 성능을 측정하는 전용 벤치마크와 데이터
- 시사점: React Agent 성능 평가를 위해 구축된 데이터셋으로, 사내 모델 학습을 위해 수집한 고품질 데이터를 기반으로 평가용 데이터셋이 자연스럽게 탄생한 형태로 추정. 통신 업무에 필요한 조건들을 반영한 벤치마크로, 의미 있는 기준점을 제시
- 내용: LLM 기반 Agent는 빠르게 고도화되고 있지만, 통신 분야에 특화된 성능 평가 기준은 아직 부족합니다. SK텔레콤은 통신 서비스에 필요한 Agent의 핵심 능력을 Action, Planning, Reasoning, Instruction Following, RAG의 다섯 가지로 정의하고, 이를 반영한 TelAgentBench를 구축했습니다. 한국어 기반 명령 이해, 로밍 규정, API 호출 등 실제 상용 서비스에서 요구되는 조건을 포함해 상용·오픈소스 모델을 다각도로 평가했으며, 이를 통해 모델별 공통 패턴 및 고유한 장단점을 분석







https://skaisummit.com/session
SK AI SUMMIT 2025 AI의 미래를 경험하다
11월 3일~4일, 서울 COEX에서 SK AI SUMMIT 참가 신청하기!
www.skaisummit.com
728x90
'Tech Dive > SK SUMMIT' 카테고리의 다른 글
| [SK AI SUMMIT 2025] AI의 미래를 경험하다 - Day 1 (0) | 2025.11.07 |
|---|
'Tech Dive/SK SUMMIT' Related Articles
more
