
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- RLHF
- context engineering
- Multi-Head Attention
- Engineering at Anthropic
- 트랜스포머
- reinforcement learning from human feedback
- MQA
- rotary position embedding
- model context protocol
- transformer
- extended thinking
- catastrophic forgetting
- PEFT
- attention
- Positional Encoding
- langgraph
- test-time scaling
- MHA
- flashattention
- re-ranking
- CoT
- self-attention
- fréchet inception distance
- BLEU
- 토크나이저
- SK AI SUMMIT 2025
- Langchain
- Embedding
- chain-of-thought
- gqa
- Today
- Total
AI Engineer 공간 "사부작 사부작"
멀티모달 AI, 눈으로 읽고 마음으로 이해하다: CLIP, Flamingo, LLaVA 완전 정복! 본문
멀티모달 AI, 눈으로 읽고 마음으로 이해하다: CLIP, Flamingo, LLaVA 완전 정복!
ChoYongHo 2025. 5. 21. 22:22멀티모달의 심장, 텍스트-이미지 융합: CLIP, Flamingo, LLaVA 심층 해부
인공지능(AI) 분야에서 멀티모달 시스템은 인간과 유사한 정보 이해를 목표로 하며, 시각 정보(이미지)와 언어 정보(텍스트)의 정교한 융합은 AI가 세상을 다면적으로 인식하는 데 핵심입니다. 멀티모달 AI 모델인 CLIP, Flamingo, LLaVA가 어떻게 이질적인 두 정보를 결합하는지, 그 핵심 아키텍처와 융합 메커니즘을 살펴보겠습니다.
CLIP: 공유 임베딩 공간에서 이미지와 텍스트의 의미론적 조우
OpenAI에 의해 개발된 CLIP(Contrastive Language-Image Pre-training)은 이미지와 텍스트가 서로의 의미를 이해할 수 있도록 공통의 의미론적 공간을 구축하는 모델입니다.

핵심 아이디어: 이미지와 텍스트 데이터를 하나의 고차원 벡터 공간(공유 임베딩 공간)에 투영하여, 의미적으로 유사한 이미지-텍스트 쌍은 가깝게, 그렇지 않은 쌍은 멀게 배치함으로써 둘 사이의 연관성을 학습합니다.
개념: CLIP은 독립적인 두 개의 인코더, 즉 이미지의 시각적 특징을 추출하는 이미지 인코더(예: Vision Transformer, ResNet)와 텍스트의 언어적 특징을 추출하는 텍스트 인코더(예: Transformer)로 구성됩니다. 이 모델의 핵심은 방대한 이미지-텍스트 쌍 데이터셋을 활용한 대조 학습(contrastive learning)입니다. 이 학습 방식을 통해, 명시적인 레이블 없이도 모델은 다양한 시각적 개념과 그에 상응하는 텍스트 설명을 의미론적으로 연결 짓는 능력을 배양하며, 이는 제로샷(zero-shot) 일반화 성능의 기반이 됩니다.
작동 방식: CLIP은 듀얼 인코더 아키텍처를 기반으로 합니다. 이미지 인코더는 입력 이미지로부터 시각적 특징 벡터를 추출하고, 텍스트 인코더는 입력 텍스트로부터 텍스트 특징 벡터를 추출합니다. 학습 과정은 대조적 사전 학습을 통해 이루어지는데, 실제 쌍을 이루는 이미지와 텍스트 특징 벡터 간의 코사인 유사도는 최대화하고, 무작위로 매칭된 쌍 간의 유사도는 최소화하도록 모델 파라미터를 최적화합니다. 이 과정은 주로 InfoNCE 손실 함수와 같은 메커니즘을 통해 진행됩니다. 융합 자체는 두 모달리티의 특징 벡터가 명시적으로 결합되는 것이 아니라, 공유 임베딩 공간 내에서의 상대적인 거리 또는 유사도 자체가 융합된 정보의 표현으로 간주되는 암묵적 방식입니다.
예시: '해변에서 파도를 타는 서퍼'의 이미지와 "해변에서 서핑을 즐기는 사람"이라는 텍스트 설명이 한 쌍으로 주어졌다고 가정해 봅시다. CLIP은 학습을 통해 이 이미지로부터 추출된 벡터와 텍스트로부터 추출된 벡터가 공유 임베딩 공간상에서 서로 근접하도록 조정합니다. 반대로, 동일한 서퍼 이미지와 "눈 덮인 산 정상"이라는 텍스트 쌍의 벡터는 공간상에서 서로 멀어지도록 학습합니다. 모델 사용 시, 예를 들어 "사과 그림" 이미지가 주어지면, 이 이미지의 임베딩과 "빨갛고 둥근 과일"이라는 텍스트의 임베딩은 공간상에서 가깝게 위치하여 모델이 이 둘을 연관된 것으로 이해합니다. 이를 통해 특정 이미지에 가장 적합한 텍스트 설명을 찾거나(예: 제로샷 이미지 분류), 특정 텍스트 설명에 맞는 이미지를 검색하는(예: 이미지-텍스트 검색) 등의 작업이 가능해집니다.
비유: CLIP의 작동 원리는 고도로 정교화된 '다국어 시맨틱 색인 시스템'에 비유할 수 있습니다. 이 시스템에는 세상의 다양한 시각적 객체 및 장면(이미지)과 이를 기술하는 언어적 표현(텍스트)들이 각자의 고유한 '의미 좌표'를 부여받아 등록됩니다. 예를 들어, '붉은색 스포츠카' 이미지, "red sports car"라는 영어 구문, "빨간 스포츠카"라는 한국어 구문은 이 시스템의 의미 공간에서 매우 인접한 위치에 매핑됩니다. 따라서 사용자가 특정 '붉은색 스포츠카' 이미지를 시스템에 제시하면, 시스템은 해당 이미지의 의미 좌표와 가장 가까운 곳에 위치한 텍스트 기술어들을 효율적으로 탐색하여 반환할 수 있습니다.
주요 특징 및 강점: 가장 두드러지는 강점은 특정 작업에 대한 추가적인 미세 조정 없이도 다양한 시각적 인식 작업에 즉시 적용 가능한 강력한 제로샷(zero-shot) 일반화 능력입니다.
Flamingo: 시각적 맥락을 능동적으로 통합하는 인터리빙 트랜스포머
DeepMind가 선보인 Flamingo 모델은 사전 훈련된 강력한 언어 모델(LLM)이 텍스트를 처리하는 과정에 이미지 정보를 동적으로 통합하여, 보다 맥락 인지적인 이해와 생성을 가능하게 하는 정교한 아키텍처입니다.
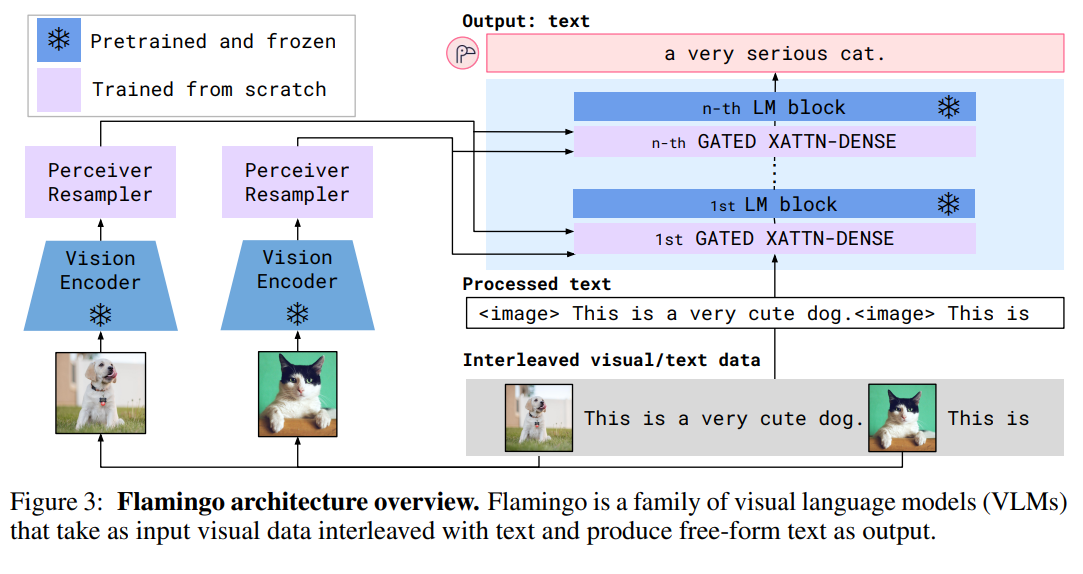
핵심 아이디어: 사전 훈련된 대규모 언어 모델의 텍스트 처리 흐름 중간에, 관련된 시각 정보를 선택적으로 주입하고 참조할 수 있는 메커니즘을 도입하여, 마치 인간이 대화 중 이미지를 참고하듯 자연스러운 멀티모달 상호작용을 구현합니다.
개념: Flamingo는 고정된(frozen) 상태의 강력한 비전 인코더와 사전 훈련된 LLM(예: Chinchilla)을 핵심 구성 요소로 활용합니다. 시각 정보는 비전 인코더를 거쳐 퍼시버 리샘플러(Perceiver Resampler)에 의해 고정된 개수의 압축된 시각 토큰(visual tokens)으로 변환됩니다. Flamingo 아키텍처의 핵심 혁신은 LLM의 기존 트랜스포머 블록들 사이에 새로이 삽입된 게이트 크로스 어텐션(gated cross-attention) 레이어입니다. 이 레이어를 통해 LLM의 텍스트 토큰은 현재 처리 중인 텍스트 맥락과 가장 연관성이 높은 시각 토큰들을 능동적으로 참조하고, 그 정보를 후속 토큰 생성에 반영할 수 있게 됩니다.
작동 방식: Flamingo는 모듈화된 구성 요소를 특징으로 합니다: 사전 훈련 후 고정된 비전 인코더가 이미지에서 시각적 특징을 추출하고, 퍼시버 리샘플러는 이를 소수의 압축된 시각 토큰으로 변환합니다. 핵심 융합은 사전 훈련된 언어 모델의 트랜스포머 블록 사이에 추가된 게이트 크로스 어텐션 레이어에서 이루어집니다. 언어 모델이 텍스트 시퀀스를 처리할 때, 각 텍스트 토큰은 쿼리(Query)로 작용하여 퍼시버 리샘플러가 제공한 시각 토큰들(키 Key 및 값 Value)에 대해 크로스 어텐션을 수행합니다. 이를 통해 현재 텍스트 맥락과 가장 관련 있는 시각 정보를 동적으로 식별하고 통합합니다. 게이팅 메커니즘은 크로스 어텐션의 출력이 언어 모델의 다음 계층으로 전달되기 전에 그 영향력을 조절하여, 시각 정보와 언어 정보 간의 균형을 효과적으로 맞추고 학습 안정성을 높입니다. 또한, Flamingo는 텍스트와 이미지가 번갈아 나타나는 인터리빙(interleaved) 시퀀스 처리가 가능하도록 설계되었습니다.
예시: "이 이미지에 있는 고양이는 어떤 행동을 하고 있나요?"라는 질문과 함께 창가에 앉아 있는 고양이 이미지가 입력되었다고 가정해 봅시다. Flamingo의 LLM이 질문 텍스트를 순차적으로 처리하다 '고양이'라는 단어에 도달하면, 게이트 크로스 어텐션 메커니즘이 활성화됩니다. 이때, '고양이' 텍스트 토큰은 이미지의 시각 토큰들 중에서 창가에 앉아 있는 고양이의 모습과 관련된 특징들에 높은 어텐션 가중치를 부여합니다. 이렇게 선택적으로 통합된 시각 정보는 게이팅 메커니즘을 통해 그 영향력이 조절된 후, LLM의 다음 처리 단계로 전달되어 "이미지 속 고양이는 창가에 앉아 바깥을 응시하고 있습니다."와 같은 구체적이고 맥락에 부합하는 답변을 생성하는 데 기여합니다.
비유: Flamingo의 작동 방식은 숙련된 수사반장(LLM)과 첨단 영상 분석팀(비전 인코더, 퍼시버 리샘플러)이 협력하여 복잡한 사건을 해결하는 과정에 빗댈 수 있습니다. 수사반장은 사건 보고서(텍스트)를 면밀히 검토하며 수사의 방향을 설정합니다. 그러다 결정적인 단서가 필요하거나 특정 진술의 사실 확인이 요구될 때, 영상 분석팀에게 특정 CCTV 영상(이미지)의 특정 구간이나 객체(시각 특징)에 대한 정밀 분석을 요청합니다(크로스 어텐션). "용의자가 현장을 벗어날 때 사용한 차량의 번호판을 식별하라"는 지시에 따라 영상 분석팀은 해당 시각 정보를 추출하여 보고하고, 수사반장은 이 정보를 기존의 수사 내용과 통합하여 다음 수사 단계를 결정합니다.
주요 특징 및 강점: 소수의 예시(few-shot)만으로도 새로운 시각적 질의응답이나 작업에 빠르게 적응하는 능력이 뛰어나며, 이미지와 텍스트가 복잡하게 얽힌 멀티모달 입력을 효과적으로 처리할 수 있습니다.
LLaVA: 시각 정보를 LLM의 언어 체계로 변환하여 통합적 이해 도모
LLaVA(Large Language and Vision Assistant)는 대규모 언어 모델(LLM)이 이미지에 대한 깊이 있는 이해와 추론을 수행할 수 있도록, 추출된 이미지 특징을 LLM이 기존에 처리하던 텍스트 표현 공간으로 직접 투영(projection)하는 혁신적인 접근 방식을 제시합니다.

핵심 아이디어: 이미지에서 추출한 고수준의 시각적 특징들을 LLM이 이해할 수 있는 '시각적 단어(visual tokens)'의 형태로 변환하여, LLM이 텍스트 정보와 시각 정보를 마치 하나의 통합된 언어처럼 자연스럽게 처리하도록 합니다.
개념: LLaVA는 사전 훈련된 강력한 비전 인코더(예: CLIP의 ViT-L/14)를 사용하여 입력 이미지로부터 풍부한 시각적 특징(Zv)을 추출합니다. 이 추출된 시각적 특징은 학습 가능한 간단한 선형 투영 계층(linear projection layer, W)을 통해 LLM의 단어 임베딩과 동일한 차원의 벡터(Hv)로 변환됩니다. 이렇게 변환된 시각적 특징들은 LLM에게 일련의 '시각 토큰'으로 인식되며, 이는 LLM이 기존의 텍스트 처리 메커니즘을 확장하여 시각 정보를 이해하는 기반을 마련합니다.
작동 방식: LLaVA는 고정된 비전 인코더(예: CLIP ViT-L/14)를 사용하여 입력 이미지(Xv)에서 시각적 특징(Zv)을 추출합니다. 이 특징 Zv는 학습 가능한 선형 투영 계층(W)을 통과하여 LLM의 단어 임베딩 공간과 동일한 차원의 시각 토큰(Hv)으로 변환됩니다. 이 시각 토큰 시퀀스 Hv는 사용자의 텍스트 지시사항 또는 질문(Xq)으로부터 생성된 텍스트 토큰 시퀀스(Hq)와 결합되어 LLM(f_phi)의 입력으로 사용됩니다. LLM은 내부의 셀프 어텐션 메커니즘을 통해 결합된 시퀀스 내의 텍스트 토큰과 시각 토큰 간의 복잡한 상호 관계를 학습하고 전체적인 맥락을 이해합니다. LLaVA는 2단계 학습 전략을 사용합니다: 특징 정렬 사전 학습 단계에서는 이미지-캡션 쌍 데이터를 사용하여 투영 계층 W만을 학습시켜 시각 특징을 LLM의 표현 공간에 정렬시키고, 종단간 시각적 지시 미세 조정 단계에서는 투영 계층과 LLM 전체를 함께 미세 조정하여 복잡한 시각적 지시에 대한 응답 능력을 향상시킵니다.
예시: 사용자가 공원에서 프리스비를 물고 있는 강아지 이미지와 함께 "이 강아지는 무엇을 하고 있으며, 어떤 품종으로 보이나요?"라는 질문을 입력했다고 가정해 봅시다. LLaVA는 먼저 비전 인코더를 통해 강아지 이미지에서 시각 특징 Zv를 추출하고, 이를 투영 계층 W를 거쳐 시각 토큰 Hv로 변환합니다. 이 시각 토큰 Hv는 질문 텍스트 토큰 Hq와 결합되어 하나의 입력 시퀀스를 구성합니다. LLM은 이 결합된 시퀀스를 입력받아, "이 강아지는 공원에서 프리스비를 물고 즐겁게 놀고 있으며, 보더콜리 품종으로 보입니다."와 같이 이미지 내용에 대한 상세한 이해와 추론을 반영한 답변(Xa)을 생성할 수 있습니다.
비유: LLaVA의 작동 방식은 언어학자(LLM)가 고대의 희귀 언어로 작성된 석판(시각 정보가 포함된 입력)을 해독하는 과정에 비유할 수 있습니다. 이 석판에는 일반적인 문자(텍스트 토큰)와 함께, 의미를 함축하고 있는 특수한 상형문자(이미지)가 새겨져 있습니다. 먼저, 고고학 조수(비전 인코더)가 상형문자의 핵심적인 형태와 패턴(시각 특징)을 세밀하게 분석합니다. 그런 다음, 고대 상형문자 전문가(선형 투영 계층)가 이 분석된 특징들을 언어학자가 이해할 수 있는 기호 체계, 즉 '해독된 시각 기호(시각 토큰)'로 변환합니다. 이제 언어학자는 일반 문자와 해독된 시각 기호들을 순서대로 읽어 내려가며(통합된 입력 시퀀스 처리), 석판 전체에 담긴 역사적 사건이나 문화적 의미를 종합적으로 해석해냅니다.
주요 특징 및 강점: 시각적 지시어 튜닝을 통해 복잡한 시각적 추론, 상세한 이미지 설명 생성, 그리고 여러 턴에 걸친 시각 기반 대화(multi-turn visual conversation) 등 고도화된 멀티모달 상호작용 능력을 효과적으로 발휘합니다.
마무리하며
CLIP, Flamingo, LLaVA는 멀티모달 AI가 텍스트와 이미지 정보를 융합하는 다양한 스펙트럼을 보여줍니다. 공유 임베딩 공간을 통한 암묵적 정렬, 인터리빙 트랜스포머와 크로스 어텐션을 통한 능동적 상호작용, 그리고 시각 정보의 LLM 언어 공간으로의 직접적인 투영은 각각 독특한 강점과 적용 분야를 가집니다.
https://arxiv.org/abs/2103.00020
Learning Transferable Visual Models From Natural Language Supervision
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual co
arxiv.org
https://arxiv.org/abs/2204.14198
Flamingo: a Visual Language Model for Few-Shot Learning
Building models that can be rapidly adapted to novel tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. We propo
arxiv.org
https://arxiv.org/abs/2304.08485
Visual Instruction Tuning
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use l
arxiv.org
'Theory > Multimodal Models' 카테고리의 다른 글
| 멀티모달 AI의 꿈과 현실: 설계부터 훈련까지 핵심 난제 완전 정복! (0) | 2025.05.21 |
|---|