
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- catastrophic forgetting
- MHA
- chain-of-thought
- Embedding
- reinforcement learning from human feedback
- gqa
- Positional Encoding
- transformer
- 트랜스포머
- flashattention
- MQA
- BLEU
- 토크나이저
- SK AI SUMMIT 2025
- Multi-Head Attention
- CoT
- rotary position embedding
- re-ranking
- test-time scaling
- PEFT
- Engineering at Anthropic
- model context protocol
- fréchet inception distance
- self-attention
- attention
- extended thinking
- langgraph
- Langchain
- RLHF
- context engineering
- Today
- Total
AI Engineer 공간 "사부작 사부작"
AI 조율의 미학: RLHF부터 GRPO까지, LLM 정렬 기법 별 핵심과 선택 전략 본문
AI 조율의 미학: RLHF부터 GRPO까지, LLM 정렬 기법 별 핵심과 선택 전략
ChoYongHo 2025. 5. 17. 16:05LLM 정렬 기법 전격 비교: RLHF, RLAIF, DPO, GRPO 파헤치기
대규모 언어 모델(LLM)이 우리 삶에 깊숙이 들어오면서, 이 AI가 인간의 의도와 가치에 부합하도록 만드는 '정렬(alignment)' 과정이 무엇보다 중요해졌습니다. 정렬이란 LLM이 단순히 똑똑한 것을 넘어, 우리에게 유용하고(helpful), 정직하며(honest), 무해하도록(harmless) 만드는 핵심 과정입니다. 마치 잘 훈련된 충견처럼, 강력한 능력을 올바른 방향으로 사용하도록 길들이는 것이죠.
이를 위해 다양한 정렬 기법들이 연구되고 적용되고 있습니다. 마치 각기 다른 훈련법을 가진 조련사들처럼, 각 기법은 고유한 방식으로 LLM을 다듬어 나갑니다. 이번 글에서는 대표적인 정렬 기법인 RLHF, RLAIF, DPO, GRPO를 비교하며 각 핵심 메커니즘과 장단점을 알기 쉽게 설명해 드리겠습니다.
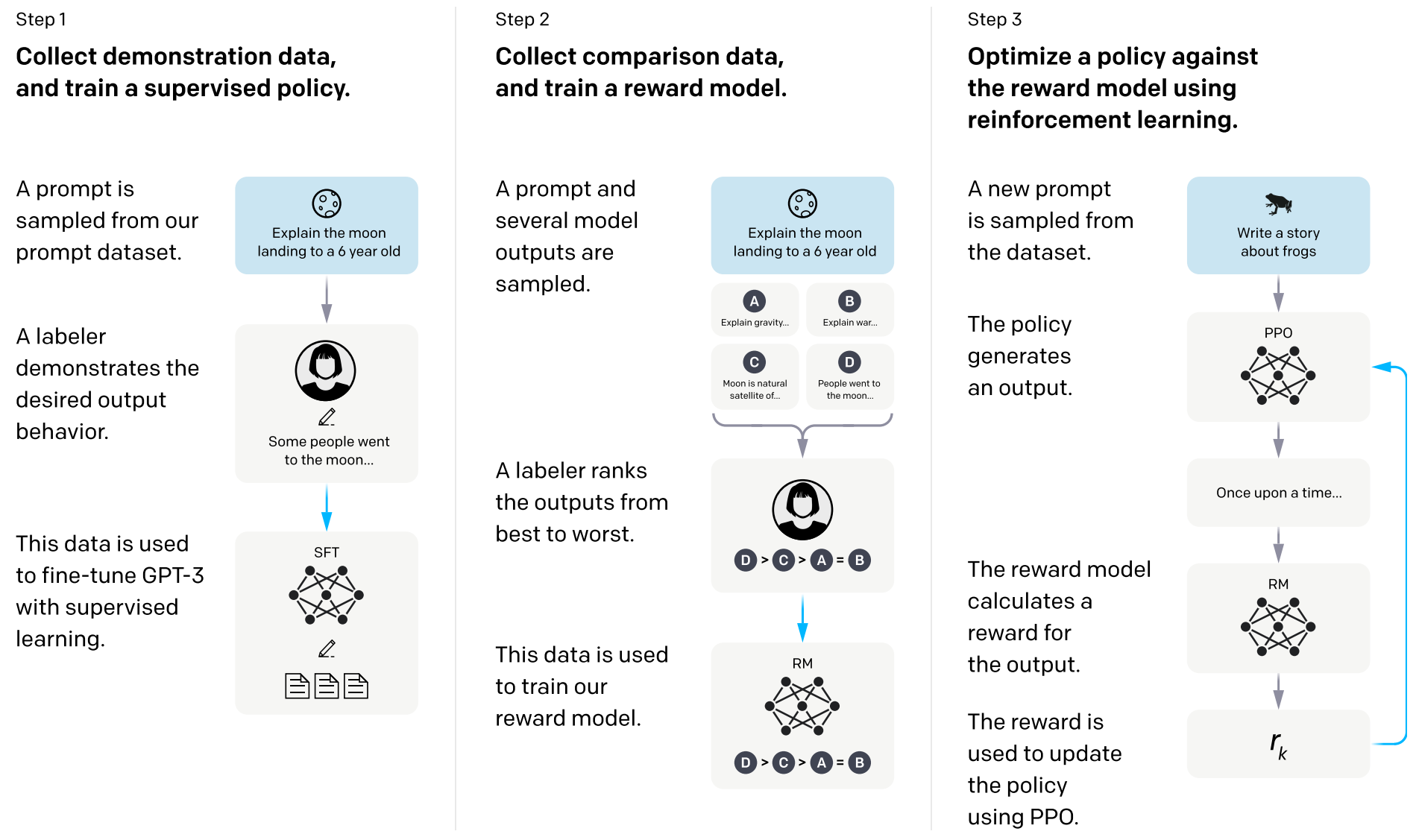
인간 피드백 기반 강화 학습 (Reinforcement Learning from Human Feedback, RLHF): 인간의 손길로 빚어내는 섬세함
RLHF는 이름에서 알 수 있듯, 인간의 직접적인 피드백을 통해 LLM을 정렬하는 방식입니다. 마치 도예가가 직접 손으로 빚어 섬세한 형태를 만들듯, 인간의 미묘한 선호도를 모델에 반영합니다.
핵심 메커니즘
- 선호도 데이터 수집: 먼저, LLM이 생성한 여러 응답들에 대해 인간 평가자가 어떤 응답이 더 나은지, 혹은 얼마나 좋은지를 평가하여 선호도 데이터를 구축합니다. 예를 들어, "오늘 날씨 어때?"라는 질문에 LLM이 생성한 A: "맑고 화창합니다."와 B: "오늘 날씨는 서울 기준 25도로 예상되며, 미세먼지 농도는 보통입니다. 외출 시 참고하세요." 중 인간 평가자는 B가 더 유용하다고 선택할 수 있습니다.
- 보상 모델(Reward Model, RM) 학습: 수집된 선호도 데이터를 바탕으로, 어떤 응답이 인간의 선호에 더 부합하는지를 예측하는 별도의 '보상 모델'을 학습시킵니다1. 이 보상 모델은 일종의 'AI 심판' 역할을 하며, 좋은 응답에는 높은 점수를, 그렇지 않은 응답에는 낮은 점수를 부여합니다.
- 강화 학습(RL)을 통한 LLM 미세 조정: 학습된 보상 모델을 강화 학습 알고리즘(주로 PPO 사용)의 '보상 함수'로 활용하여 원래 LLM을 미세 조정합니다. LLM은 보상 모델로부터 더 높은 점수를 받는 응답을 생성하도록 학습하며, 점차 인간의 선호에 맞는 방향으로 개선됩니다.
비유: 어린아이가 그림을 그릴 때, 부모님이 옆에서 "이 그림은 색감이 참 좋네!", "저 그림은 조금 더 구체적으로 그리면 좋겠다!"라고 칭찬과 조언을 해주는 것과 비슷합니다. 여기서 부모님의 칭찬과 조언이 '인간 피드백'이고, 이를 통해 아이가 어떤 그림이 좋은 그림인지 기준(보상 모델)을 배우고, 다음 그림을 그릴 때 더 나은 그림(강화 학습)을 그리려 노력하는 과정입니다.
장점:
- 인간의 미묘하고 복잡한 선호도를 직접 반영하여 정렬 품질이 높을 수 있습니다. 특히 윤리적 판단이나 창의성처럼 정량화하기 어려운 영역에서 효과적입니다.
- 모델의 응답을 인간의 직관에 더 가깝게 만들 수 있습니다.
단점:
- 고품질의 인간 선호도 데이터를 수집하는 데 많은 시간과 비용이 소요됩니다.
- 전체 프로세스가 여러 단계로 구성되어 복잡하며, 학습된 보상 모델의 품질에 최종 LLM 성능이 크게 좌우됩니다.
- 인간 평가자의 주관성이나 불일치가 모델 학습에 편향을 유발할 수 있습니다.
AI 피드백 기반 강화 학습 (Reinforcement Learning from AI Feedback, RLAIF): AI가 AI를 가르치는 확장성
RLAIF는 RLHF의 확장성과 비용 문제를 해결하기 위해 등장한 기법입니다. 인간 평가자 대신, 잘 훈련된 다른 AI 모델을 사용하여 피드백을 생성하는 방식입니다.

핵심 메커니즘
RLHF와 기본적인 흐름은 유사하지만, 가장 큰 차이점은 '누가 피드백을 제공하는가'입니다.
- AI 기반 선호도 레이블 생성: 비용이 많이 드는 인간 평가자 대신, 이미 강력한 성능을 가진 다른 AI 모델(예: 더 크거나 특정 기준에 맞춰진 LLM)을 사용하여 LLM 응답에 대한 선호도 레이블을 자동으로 생성합니다.
- 보상 모델(RM) 학습 및 LLM 미세 조정: 이후 과정은 RLHF와 동일합니다. AI가 생성한 선호도 데이터로 보상 모델을 학습시키고, 이 보상 모델을 기반으로 강화 학습을 통해 원래 LLM을 미세 조정합니다.
비유: RLHF가 부모님의 직접적인 지도를 받는 것이라면, RLAIF는 마치 우수한 AI 학습 보조 로봇이 아이의 그림을 평가하고 개선점을 알려주는 상황과 같습니다. 이 AI 보조 로봇은 이미 많은 좋은 그림 데이터를 학습했거나, 특정 평가 기준(예: '헌법 AI'처럼 정해진 원칙)을 따르도록 설계될 수 있습니다.
장점:
- 인간의 개입을 최소화하여 대규모 선호도 데이터 생성이 용이하며, 이를 통해 학습 과정을 자동화하고 확장성을 크게 높일 수 있습니다.
- 시간과 비용을 절감할 수 있습니다.
- AI 피드백은 일관성이 높을 수 있습니다.
단점:
- 최종 정렬 품질이 레이블 생성에 사용된 AI 모델의 성능과 그 모델이 가진 잠재적 편향에 크게 의존합니다. 만약 피드백을 주는 AI 모델이 완벽하지 않다면, 그 한계가 그대로 학습될 수 있습니다.
- 복잡하고 미묘한 인간의 가치 판단을 AI가 완벽히 대체하기 어려울 수 있습니다.
직접 선호도 최적화 (Direct Preference Optimization, DPO): 보상 모델 없이 직접, 더 간단하게
DPO는 RLHF/RLAIF의 복잡한 다단계 과정을 단순화한 혁신적인 접근법입니다. 별도의 보상 모델을 명시적으로 학습시키거나 강화 학습 단계를 거치지 않고, 선호도 데이터를 사용하여 LLM을 직접 미세 조정합니다.

핵심 메커니즘
- 선호도 데이터 준비: RLHF와 마찬가지로, 동일한 프롬프트에 대해 인간 (또는 AI)이 더 선호하는 응답(chosen response)과 덜 선호하는 응답(rejected response) 쌍으로 구성된 데이터셋을 사용합니다.
- 직접적인 LLM 미세 조정: DPO는 특정 손실 함수(주로 분류 손실 기반)를 사용하여, LLM이 선호되는 응답을 생성할 확률은 높이고, 비선호 응답을 생성할 확률은 낮추도록 직접 학습합니다. 즉, "이런 응답은 좋으니 더 자주 만들고, 저런 응답은 안 좋으니 덜 만들어"라고 LLM에게 직접 가르치는 방식입니다.
비유: 운전 연습을 할 때, 교관이 옆에서 "지금처럼 차선 유지하는 건 아주 좋아요 (선호 응답). 하지만 방금처럼 급브레이크 밟는 건 위험해요 (비선호 응답)."라고 직접적인 피드백을 주는 것과 유사합니다. 복잡한 '운전 점수 채점 시스템(보상 모델)'을 만들거나, 점수를 기반으로 조금씩 운전 습관을 교정(강화 학습)하는 대신, 매 순간의 행동에 대한 명확한 좋고 싫음의 피드백으로 바로 운전 실력을 향상시키는 것입니다.
장점:
- 별도의 보상 모델 학습 및 강화 학습 단계가 없어 구현이 RLHF/RLAIF보다 훨씬 간단하고 직관적입니다.
- 학습 과정이 더 안정적이고 계산 비용이 낮으며, 하이퍼파라미터 튜닝의 부담이 적습니다.
단점:
- 때로는 RLHF만큼 정교한 제어나 극한의 성능을 달성하기 어려울 수 있다는 보고가 있습니다. 강화 학습의 탐험적인 특성 없이 직접 최적화하기 때문에, 보상 모델이 암시적으로 포착할 수 있는 미묘한 선호 패턴을 놓칠 수 있습니다.
- 경우에 따라 그래디언트 불균형 문제가 발생하여 학습 안정성을 저해할 수 있다는 연구 결과도 있습니다.
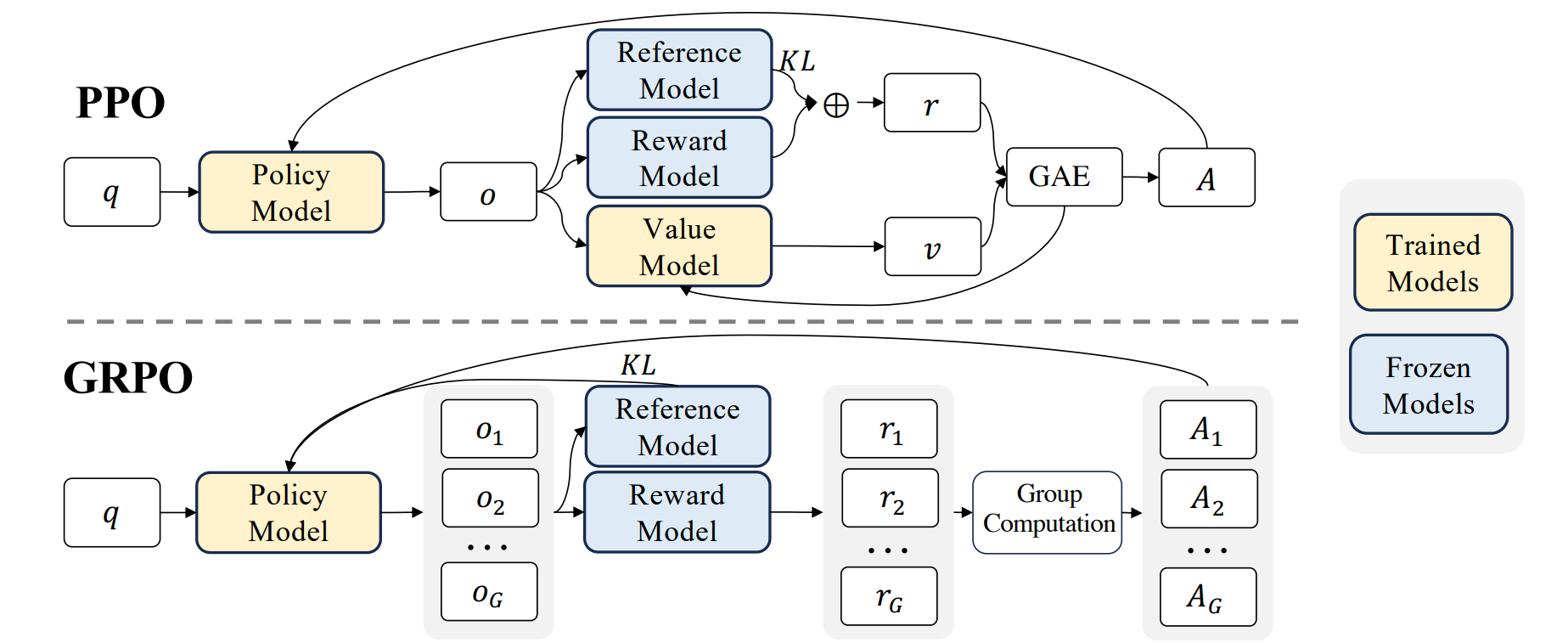
그룹 상대 정책 최적화 (Group Relative Policy Optimization, GRPO): 비평가 없이 효율적인 그룹 비교
GRPO는 강화 학습 기반 접근법이면서도, 기존 RLHF에서 필요했던 별도의 가치 함수(value/critic model) 없이 정책을 최적화하는 것을 목표로 합니다. 이는 특히 자원 효율성 측면에서 장점을 가집니다.
핵심 메커니즘
- 그룹 단위 응답 샘플링 및 평가: 하나의 입력(프롬프트)에 대해 여러 개의 응답 후보(행동 그룹)를 동시에 생성합니다.
- 상대적 보상 활용: 이 그룹 내 응답들의 보상 값(예: 인간 또는 AI 선호도 점수)을 비교합니다. GRPO의 핵심은 개별 응답의 절대적인 가치를 평가하는 대신, 그룹 내 응답 점수의 통계량(예: 평균)을 암시적인 '베이스라인(baseline)'으로 사용하여 각 응답의 상대적 우수성을 판단하고 이를 바탕으로 정책 그래디언트를 계산합니다. 즉, 명시적인 비평가 모델 없이 그룹 내 상대 평가를 통해 학습 신호를 얻습니다.
비유: 학교에서 여러 학생이 그린 그림들을 한데 모아 전시한다고 상상해 봅시다. RLHF의 비평가 모델은 마치 전문 비평가가 각 그림에 절대적인 점수를 매기는 것과 같습니다. 반면 GRPO는, 그 전시회에 온 관람객들이 여러 그림들을 둘러보고 "이 그룹의 그림들 중에서는 이 그림이 제일 낫네", "저 그림은 평균보다 좀 아쉽네"라고 상대적으로 평가하는 것과 비슷합니다. 별도의 '완벽한 그림' 기준 없이 그룹 내 비교만으로 어떤 그림이 더 나은지를 판단하는 것입니다.
장점:
- 별도의 가치 모델(critic network)이 필요 없어 학습 중 메모리 사용량 등 자원 효율성을 높일 수 있습니다.
- 여러 행동을 한 번에 비교하므로 샘플 효율성을 높이고 정책 업데이트의 안정성을 개선할 수 있습니다.
- 계산 비용을 낮추면서도 정렬 목표를 달성할 수 있는 잠재력을 가집니다.
단점:
- 비교적 최신 방법론으로, 실제 적용 및 최적화에 더 많은 연구와 노하우가 필요할 수 있습니다.
- 한 상태(프롬프트)에서 충분한 수의 다양한 샘플(응답 그룹)을 확보해야 효과적일 수 있습니다.
- 정확한 어드밴티지 추정의 어려움과 같은 도전 과제가 여전히 존재합니다.
마무리하며
지금까지 살펴본 것처럼, RLHF, RLAIF, DPO, GRPO는 각각 고유한 철학과 장단점을 가지고 LLM을 인간의 의도에 맞게 정렬합니다.
- RLHF: 인간의 섬세한 판단을 직접 반영하여 높은 품질의 정렬을 추구하지만, 비용과 복잡성이 높습니다.
- RLAIF: AI를 활용하여 RLHF의 확장성과 비용 문제를 개선하려 하지만, AI 평가자의 품질에 의존적입니다.
- DPO: 보상 모델링과 강화 학습을 생략하여 단순성과 안정성을 추구하지만, RLHF의 정교함에는 미치지 못할 수 있습니다.
- GRPO: RL 프레임워크 내에서 그룹 비교와 효율적인 베이스라인 추정을 통해 자원 효율성을 개선하고자 합니다.
어떤 방법이 절대적으로 우월하다고 말하기는 어렵습니다. 목표로 하는 정렬 수준, 사용 가능한 데이터의 양과 질, 계산 자원, 구현의 복잡성 등을 종합적으로 고려하여 현재 상황에 가장 적합한 방법을 선택하는 것이 중요합니다.
Training language models to follow instructions with human feedback
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not ali
arxiv.org
https://arxiv.org/abs/2212.08073
Constitutional AI: Harmlessness from AI Feedback
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through self-improvement, without any human labels identifying harmful outputs. The only human ove
arxiv.org
https://arxiv.org/abs/2305.18290
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining s
arxiv.org
https://arxiv.org/abs/2402.03300
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced f
arxiv.org
'Theory > Training & Fine-Tuning' 카테고리의 다른 글
| AI 추론 능력의 비밀, RLHF와 RLVR: DeepSeek-R1은 어떻게 '생각'을 배웠나? (0) | 2025.05.17 |
|---|---|
| RLHF 보상 모델 설계의 비밀: 인간 선호를 정확히 읽는 AI의 나침반 (0) | 2025.05.17 |
| 명령어 튜닝(Instruction Tuning)'과 '거부 샘플링(Rejection Sampling): LLM을 더 똑똑하게 만드는 비법 (0) | 2025.05.17 |
| 거대한 인공지능, 길들이는 기술: 트랜스포머 훈련 안정성의 비밀 (0) | 2025.05.17 |
| LLM 성능의 또 다른 핵심 키 포인트: 데이터 정제, 전처리, 토크나이저 (0) | 2025.05.17 |